입사한지 약 1달이 넘어가는 시점에 처음으로 프로덕트 리팩토링이 아닌 업무가 할당되었다.제목에서 유추 가능하듯이 현재 사용중인 쓰레드풀에서 최적의 쓰레드의 개수를 찾는 업무였다. 처음 작업을 시작할 때는 리팩토링이 아니라는 사실만으로도 즐거웠다.하지만 이슈 분석을 하면 할수록 쉽지 않은 작업이 될것이라는 생각이 들었다. 가장 큰 난관은 내가 설정해야하는 쓰레드풀이 사용되는 기능이 외부 고객들에게 릴리즈 되지 않는 기능이였다.즉,외부로부터 발생하는 정보 없이 쓰레드풀의 최적의 개수에 대한 결론을 도출해야했다.그 과정을 천천히 풀어보겠다.
어떤 서비스 회사인가
우선 우리 회사의 서비스에 대해 간단하게 소개한다. 우선 현재 재직중인 회사는 캐시 서버를 제공한다.쉽게 말해 Redis와 동일한 서비스라고 보면 된다.그 중 나는 java 응용 개발 포지션이고,단순하게 이해를 위해 레디스와 비교하면 redis의 java client인 Jedis를 개발하는 포지션이라고 보시면 된다.또한 우리 서비스도 Redis의 RedisTemplate처럼 다양한 툴들을 제공한다.이번 작업에서 만져야할 스레드풀은 방금 언급한 다양한 툴들 중 하나의 새로운 기능에서 사용되는 스레드풀이다.
리캐싱 기능이란
방금 언급된 새로운 기능은 리캐싱 기능이다.캐시 아이템은 사용자가 캐시 서버에 아이템을 put하고 TTL이 경과하면 해당 캐시 아이템은 Evict된다.리캐싱은 evict되기 전에 해당 아이템을 DB로부터 조회해서 자동으로 갱신시켜주는 기능이다.갱신을 시켜주는 기준은 현재 캐시 아이템의 TTL이 10%이하로 남았을 경우 해당 캐시 아이템에 대한 조회 요청이 들어올 경우 랜덤한 확률을 통해 갱신 시켜준다.(PER 알고리즘의 변형) 아래 사진을 참고하자.
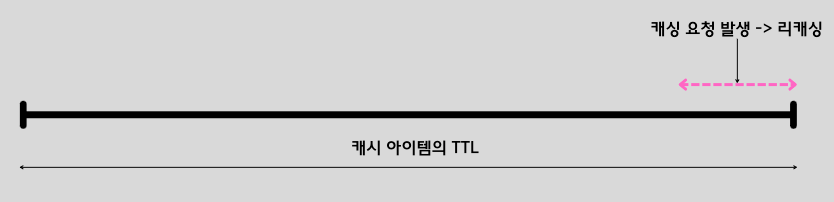
이러한 기능은 결국 사용자로 하여금 cache-miss 비율을 줄여줘 캐시 아이템의 조회 Latancy를 줄여준다.이러한 리캐싱 작업 자체를 별도의 쓰레드풀이 도맡아서 Task를 처리한다.즉,이러한 리캐싱 작업을 수행하는 스레드풀 내의 최적의 쓰레드 개수를 찾는 것이 이번 글의 주제이다.기본적인 배경 지식이 설명되었으니 본격적으로 어떻게 쓰레드풀의 다양한 인수 값들을 설정하였는지 알아보자.
사실 리캐싱 작업이라는 것이 WAS와 연결된 DB로부터 리캐싱할 데이터를 직접 가져와야하는 작업이다.결국 외부 세계의 다양한 변인들에 의해 DB Latancy는 영향을 받는다.그래서 지금부터 필자가 제안한 방법은 정답이 아니라고 얘기할 수 있다.하지만 최대한 합리적이게 접근하여 나름의 방식을 제안해본다.
리캐싱 로직은 대략 spring AOP를 사용하여 동작한다.아래에는 사용자 입장에서의 예제이다.아래처럼 캐시아이템을 적용하고 싶은 메서드에 어노테이션을 통해 적용 시킬 수 있다.
@ArcusCache
public Product getProduct(@ArcusCacheKey Long productId){
//...응용의 DB 로직
}
Spring AOP를 사용하여 해당 메서드가 실행되기 전에 먼저 remote-cache 클라우드에 해당 캐시 아이템이 존재하는지 확인한다.이후, miss가 발생한 경우에는 메서드 내부의 DB 로직이 수행된다.만약 remote-cache로부터 hit이 될 경우는 메서드 내부의 로직은 실행되지 않는다.위와 같이 캐시가 적용된 아이템을 자동으로 갱신되도록 하는 기능이 리캐싱이고 해당 로직은 AOP 내의 로직에 녹여져있다.
AOP가 적용된 로직 내에서 구현된 리캐싱 스레드풀은 Java의 ThreadPoolExecutor을 통해 생성한다. 생성된 스레드 풀은 기본으로 유지할 스레드의수(coreThreadPoolSize), 최대로 생성할 수 있는 스레드의 수(maxThreadPoolSize), 스레드가 수행할 작업이 대기할 큐(Task Queue) 등을 인수로 받게 된다.
우선 스레드 풀 내부의 TaskQueue의 경우 LinkedBlockingQueue를 통해 생성한다. 해당 큐의 경우 설정된 큐 사이즈까지 Task를 대기 시킬 수 있다. 즉, Task가 들어오자마자 스레드를 생성하지 않는다.(SynchronousQueue는 이와 반대로 동적으로 스레드 풀의 수를 조절한다.)
나머지 두 인자 coreThreadPoolSize과 maxThreadPoolSize을 설정함으로써 스레드풀의 스레드 개수를 조절할 수 있다.두 값은 초기값으로 10을 설정한다. 그러면 지금부터 어떠한 논리로 Long-Term Latancy를 가지는 DB 요청들을 반영해 두 인자들을 설정하였는지 알아보자.
정규 분포를 통한 접근
실 사용자의 데이터가 없으니 내가 첫번째로 떠올린 방법은 수학적 접근이다.DB Latancy를 내부 로직에서 가져올 수 있다면 그 로직을 활용해 DB Latancy 값들을 메모리에 저장할 수 있다.DB Latancy를 가져오는 로직은 대략 아래와 같다.해당 로직은 miss가 발생한 경우 매번 수행되는 로직이다. proceed 메서드가 실제 DB에 요청을 보내는 메서드이다.
long start = System.currentTimeMillis();
Object result = proceed((T) proceeder);
long end = System.currentTimeMillis();
위와 같이 계산된 latancy를 통해 해당 latancy가 Long-Term Latancy를 가지는 DB 요청인지 판별하기 위해 정규 분포의 개념을 사용한다.다만 위 개념은 AOP가 적용되는 메서드의 수가 많을수록(수집된 데이터가 많을 수록) 정확한 지표를 가진다. Long-Term Latancy를 판별하는 로직은 아래와 같다.
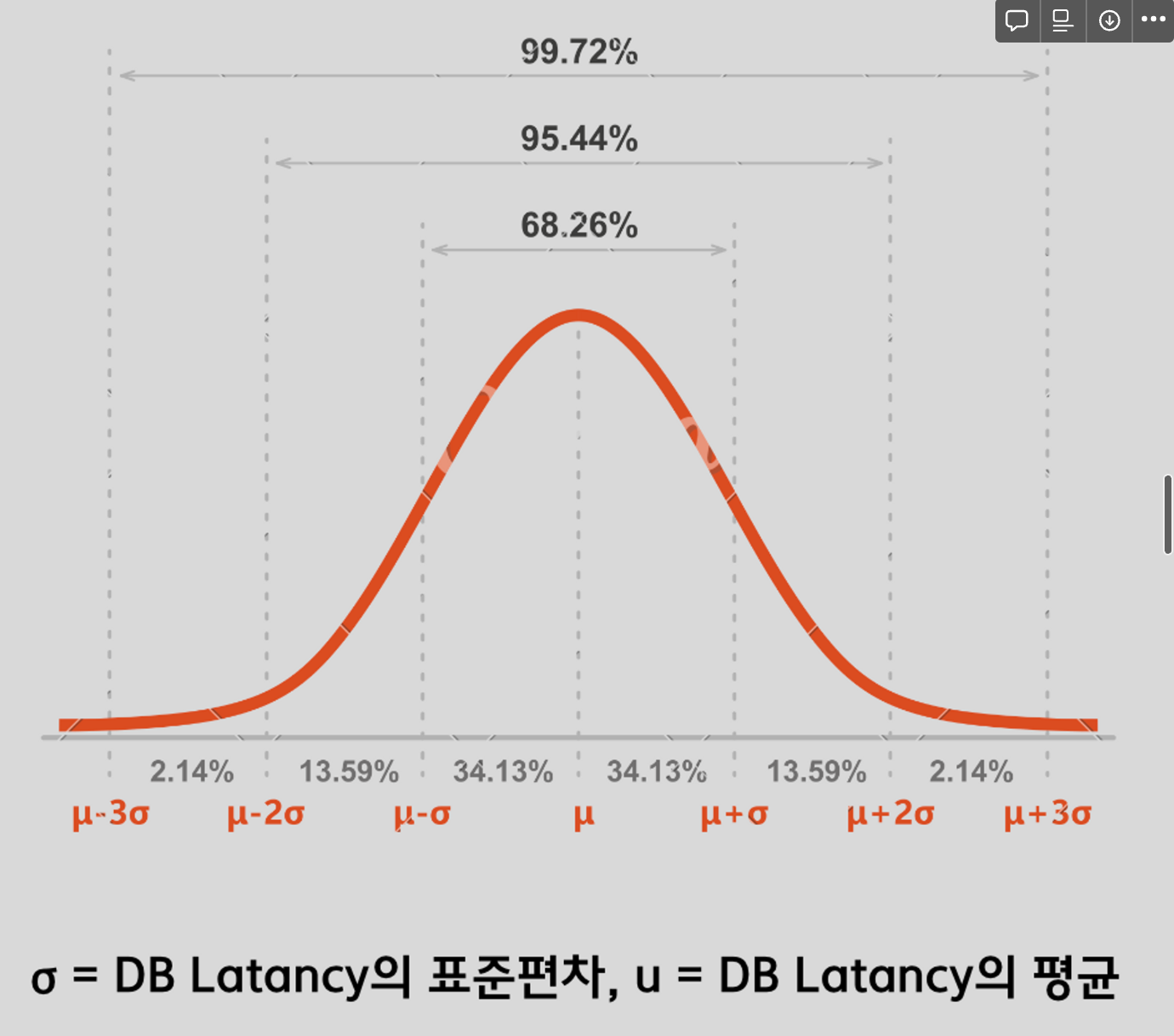
- 리캐싱 AOP가 활성화된 모든 메서드들의 첫 번째 요청이 발생
– 첫 번째 캐시 요청의 경우 모두 cache-miss가 발생하며 해당 DB Latancy 값을 파악할 수 있다.– 첫 번째 캐시 요청들의 DB Latancy를 파악해 해당 값들의 평균을 구한다.(해당 과정은 순차적으로 발생 또는 동시에 발생) - 이후의 요청들은 계산된 평균과 표준 편차에 의해 Long-Term Latancy인지 아닌지 판별되고, 해당 요청들의 Latancy을 데이터에 반영하여 새로운 표준편차와 평균을 구한다.
1. (평균 + 1σ)보다 큰 DB Latancy를 가질 경우를 Long-Term Latancy라고 판별2. (평균 + 2σ)를 기준으로 Long-Term Latancy의 기준을 잡을 경우는 4.56%의 요청만을 Long-Term Latancy라고 판별하기 때문에 너무 많은 범위를 정상적인 Latancy 요청으로 판단하기에 1σ로 판별3. 참고로 (평균 + 1.5σ) 86% 정도의 요청을 정상 Latancy로 판별 - Long-Term Latancy라고 판별된 개수만큼 maxThreadPoolSize의 수는 증가시킨다.
위와 같은 방식을 통해 Application 단에서 들어오는 요청들의 DB Latancy를 계산하여 판별한다.
위 방식의 문제점 그리고 결론
팀원들에게 위 내용을 공유하며 현재 방식이 가진 문제점에 대한 피드백은 대략 아래와 같다.
- 문제점 1 : 모든 메서드들의 첫번째 캐시 요청이 들어오기 전에 첫번째 캐시 요청이 완료된 메서드의 요청이 들어오는 경우.
- 문제점 2 : 수학적으로 정규 분포가 적용되려면 모집단으부터 표본을 뽑을 경우만 적용되는데,해당 case는 모집단이 정규분포를 따른다고 가정하여 진행됨.
- 문제점 3 : 모든 요청이 들어올 때마다 새롭게 평균과 표준편차를 갱신해야됨,메모리에 기존값을 저장한다해도 연산 오버헤드가 매번 발생.
문제 1의 경우,현재까지 들어온 요청들은 통해 해당 요청이 Long-Term인지 판별한다라는 방식을 제안했다.나머지 문제점들에 대해서는 세미나 당시에 적당한 뾰족한 해결책을 제시하지 못했다.하지만 가장 많이 피드백을 받은 문제점은 수많은 변인들을 가지는 DB Latancy를 위와 같은 접근을 통해 처리한다는 점이다.
위와 같은 문제점을 가졌음에도 불구하고 Java에서 사용되는 기본적인 쓰레드풀의 구현, 그리고 내부 큐에 의해 바뀌는 쓰레드풀의 동작방식, AOP 등 다양한 분야를 빠르게 학습하고 배우는 이슈였다고 생각한다.물론 내가 제안한 방식이 구현에 채택되지 않았고 더 합리적인 방식으로 이슈는 처리되었지만 지식적으로 충분히 얻어갈 수 있는 작업이였다고 생각한다.