서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 3주차 학습 내용을 기반으로 합니다.
1. External DNS (add-on) Policy 설정
externalDNS와 연결된 레코드들이 서비스 리소스가 삭제될 때 함께 삭제되도록 하는 옵션인 policy = "sync"를 적용 시켜본다.
addons = {
coredns = {
most_recent = true
}
kube-proxy = {
most_recent = true
}
vpc-cni = {
most_recent = true
before_compute = true
}
metrics-server = {
most_recent = true
}
external-dns = {
most_recent = true
configuration_values = jsonencode({
extraArgs = {
"--policy" = "sync"
}
})
}
}우선 처음에 위처럼 단순히 기존 테라폼 파일에 추가만 하면 아래처럼 array가 필요하다는 오류가 발생한다.

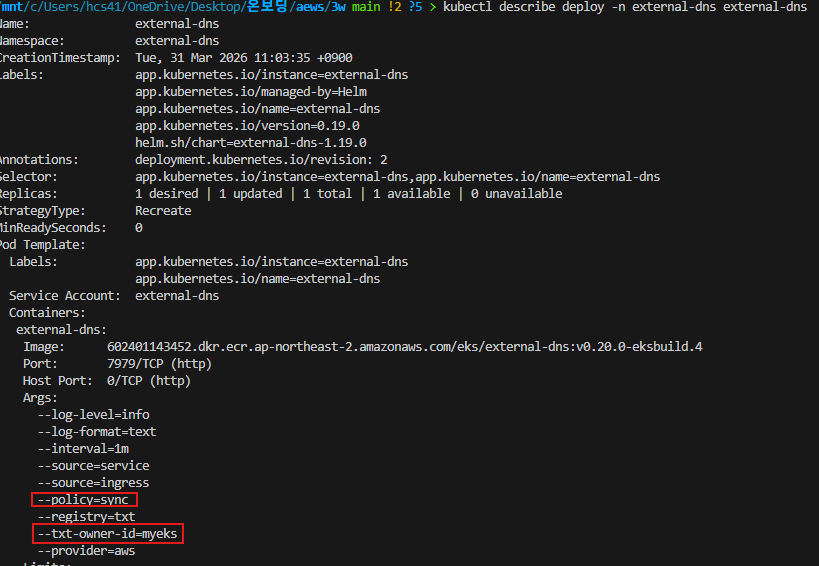
그리고 sync 옵션에서 필수적으로 함께 추가되어야하는 옵션이 있는데 이는 --txt-owner-id 이다. 왜냐하면 ExternalDNS는 기본적으로 타겟 도메인의 레코드(예: A 레코드)를 만들 때, 이거 누가 만들었는지 꼬리표를 달기 위한 TXT 레코드를 세트로 하나 더 만든다. 이 꼬리표에 들어가는 값이 바로 --txt-owner-id 이다.
만약 이 옵션이 없으면 기본값(default)으로 아이디가 설정된다. 그런데 하나의 AWS 계정을 Dev 클러스터와 Prod 클러스터가 함께 쓰는 상황이라고 가정해보자.
--policy=sync와 맞물릴 때의 sync 옵션은 "내 쿠버네티스 리소스에 없는 레코드가 Route53에 보이면 지워라!" 라는 정책이다. 만약 개발/운영 클러스터 둘 다 ID를 적어두지 않아 똑같이 default로 되어 있다면, 개발 클러스터의 ExternalDNS가 Route53을 보면서 "어? 저 운영망 쪽 도메인 레코드, 지금 내(개발) K8s 안에는 없는데? -> 지워야지!" 하고 다른 환경의 라이브 서버 도메인을 삭제해버리는 큰 문제가 발생할 수 도 있다. 그래서 위와 같은 추가적인 옵션을 통해 이 상황을 방지하자.
external-dns = {
most_recent = true
configuration_values = jsonencode({
txtOwnerId = var.ClusterBaseName
policy = "sync"
})
}참고로 기존 문법 처럼 extraArgs를 사용하면 아래와 같은 에러가 발생해서 external-dns가 정상적으로 구동되지 않는다. 아마 external dns가 헬름 차트기반 리소스라서 배열에 넣어주는게 아니라 직접 값을 설정해줘야한다.

kubectl describe deploy -n external-dns external-dns 로 아래처럼 우리가 설정한 값이 잘 적용 되었는지 확인하자.
2. tool 설치
2-1 eks-node-viewer 설치
아래 처럼 현재 구동된 클러스터의 노드들에 대한 정보를 확인시켜주는 go 로 구동된 툴이다.

회사 장비의 wsl 기준으로 설치해서 brew는 아쉽지만 사용하지 못한다. 우선 golang은 기본으로 설치시킨 뒤에 go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest 로 설치한다. 이후 sudo cp ~/go/bin/eks-node-viewer /usr/local/bin/ 로 설정해서 경로를 매번 설정하지 않도록 해준다.
2-2 kube-ops-view 배포 + ALB Ingress(MyDomain, HTTPS → HTTP)
우선 public domain이 하나가 존재해야 가능한 실습이다. 인그레스 생성 및 https 연결까지 진행하기에 domain 정보가 전파될때가지 시간이 조금 걸렸다. 아래처럼 브라우저에서 해당 도메인으로 접속이 되어야한다.
우선 헬름으로 kube-ops-view를 설치 및 배포한다.
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=ClusterIP --set env.TZ="Asia/Seoul" --namespace kube-system 이후 HTTPS 통신을 위해 acm 인증서 arn 확인을 해야한다. 아래 명령어는 현재 내계정에 존재하는 모든 acm 인증서를 조회한다. 미리 발급해둔 인증서가 있다면 echo를 했을 때 정상적으로 출력된다.
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN 이후 접속을 위한 인그레스 리소스를 배포한다.
cat <<EOF | kubectl apply -f - 11:25:58
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
labels:
app.kubernetes.io/name: kubeopsview
name: kubeopsview
namespace: kube-system
spec:
ingressClassName: alb
rules:
- host: kubeopsview.$MyDomain
http:
paths:
- backend:
service:
name: kube-ops-view
port:
number: 8080
path: /
pathType: Prefix
EOFAWS Load Balancer Controller(ALBC)를 통해 실제 AWS 클라우드 환경에 최적화된 로드밸런서(ALB)를 생성한다. 각 프로퍼티를 살펴보면 아래와 같다.
certificate-arn: $CERT_ARN: ALB에 외부 통신 암호화(HTTPS)를 위한 ACM 인증서를 부착group.name: study: 만약 이 값이 없다면 Ingress를 만들 때마다 비싼 AWS ALB가 1개씩 무조건 새로 생성됩니다.group.name을 같게 묶어두면, 여러 개의 Ingress가 1개의 ALB를 공유하여 트래픽을 나눠 갖게됨listen-ports: '[{"HTTPS":443}, {"HTTP":80}]': ALB가 80번(HTTP)과 443번(HTTPS) 포트 두 개를 모두 열어두고 사용자 접속을 대기load-balancer-name: myeks-ingress-alb: AWS 콘솔화면(EC2 -> 로드밸런서)에서 보여질 ALB의 껍데기 이름을 명시적으로 확정scheme: internet-facing: ALB가 물리적으로 퍼블릭 서브넷에 생성되며, 외부 인터넷에서 누구나 접속할 수 있는 공인 IP를 발급ssl-redirect: "443": 80 접속시 자동으로 443 리다이렉트success-codes: 200-399: ALB가 백엔드 파드들이 살아있는지(Health Check) 확인할 때, 응답 상태 코드가 200에서 399 사이로 나오면 성공으로 간주target-type: ip: 기존 쿠버네티스의 복잡한 트래픽 우회(NodePort -> Kube-Proxy -> Pod) 방식을 버리고, ALB가 파드(Pod)의 고유 IP로 트래픽을 다이렉트로 직접 통신 (AWS VPC CNI 전용 기능)
2-3 kube-prometheus-stack (그라파나 대시보드 포함) 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 80.13.3 kube myeks 13:01:35 -f monitor-values.yaml --create-namespace --namespace monitoring
우선 헬름으로 프로메테우스 설치하기 전에 monitor-values.yaml 을 먼저 생성하자. 아래 내용에는 Domain과 acm의 arn 등이 설정되어 있지 않다. 이 부분은 각자 채워넣어주면 된다.
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
additionalScrapeConfigs:
# apiserver metrics
- job_name: apiserver-metrics
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Scheduler metrics
- job_name: 'ksh-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/ksh/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Controller Manager metrics
- job_name: 'kcm-metrics'
kubernetes_sd_configs:
- role: endpoints
metrics_path: /apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
# Enable vertical pod autoscaler support for prometheus-operator
#verticalPodAutoscaler:
# enabled: true
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.hongcs.gabia-cloud.net
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:757251999979:certificate/ace008e6-263a-4ded-be54-130d1f00a3aa
alb.ingress.kubernetes.io/success-codes: "200-399"
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.hongcs.gabia-cloud.net
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:757251999979:certificate/ace008e6-263a-4ded-be54-130d1f00a3aa
alb.ingress.kubernetes.io/success-codes: "200-399"
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
아래 명령어들로 제대로 배포되었는지 확인한다.
kubectl get sts,ds,deploy,pod,svc,ep,ingress -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
# 프로메테우스 버전 확인
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version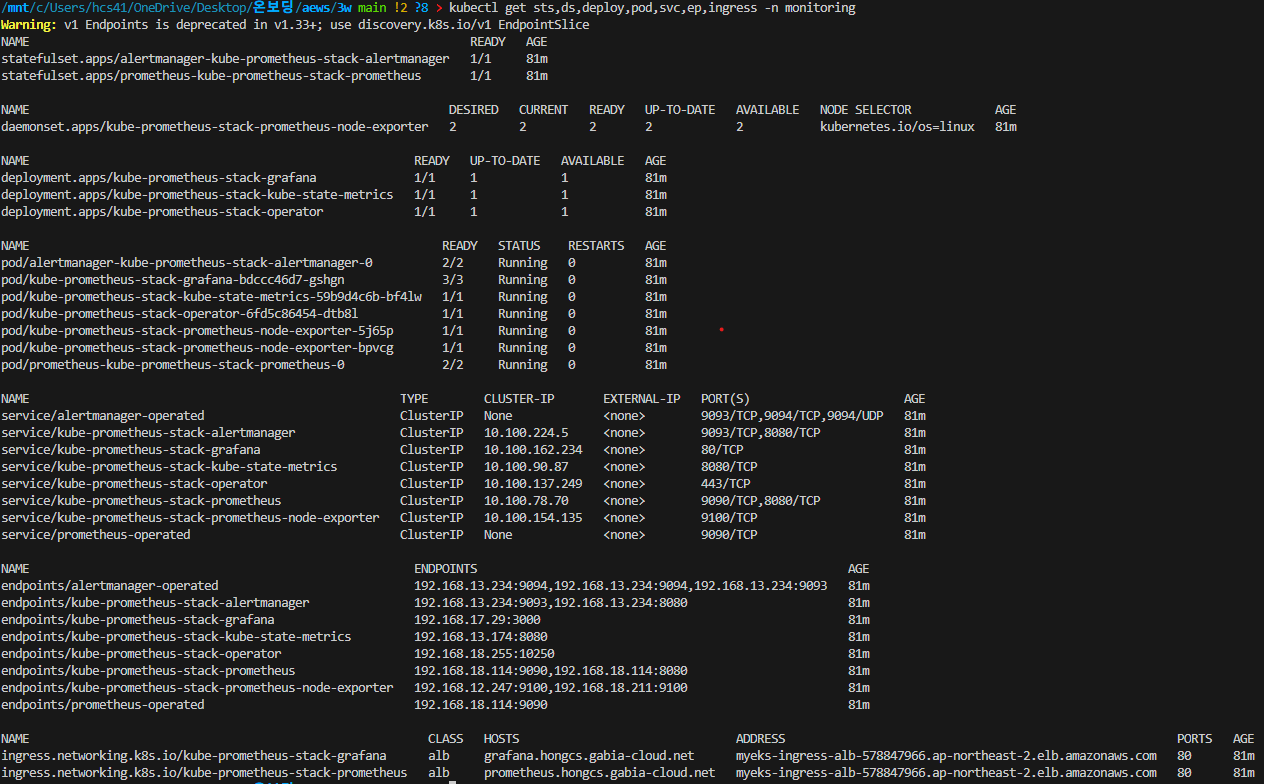
이후 그라파나 대시보드를 추가해서 배포하자.
# 대시보드 다운로드
curl -O https://raw.githubusercontent.com/dotdc/grafana-dashboards-kubernetes/refs/heads/master/dashboards/k8s-system-api-server.json
# sed 명령어로 uid 일괄 변경 : 기본 데이터소스의 uid 'prometheus' 사용
sed -i -e 's/${DS_PROMETHEUS}/prometheus/g' k8s-system-api-server.json
# my-dashboard 컨피그맵 생성 : Grafana 포드 내의 사이드카 컨테이너가 grafana_dashboard="1" 라벨 탐지!
kubectl create configmap my-dashboard --from-file=k8s-system-api-server.json -n monitoring
kubectl label configmap my-dashboard grafana_dashboard="1" -n monitoring
# 대시보드 경로에 추가 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- ls -l /tmp/dashboards이후 대시보드 접근 후 admin 계정의 비밀번호를 아래 명령어로 알아낸다.
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
3. EKS 관리형 노드 그룹
관리형 노드 그룹은 AWS가 노드의 생명주기(Lifecycle)를 전적으로 관리해 주므로 운영 편의성이 극대화 시켜준다. 우선 현재 배포한 클러스터에 노드그룹이 어떻게 구성되는지 살펴보자.
kubectl get nodes --label-columns eks.amazonaws.com/nodegroup,kubernetes.io/arch,eks.amazonaws.com/capacityType
eksctl get nodegroup --cluster myeks
aws eks describe-nodegroup --cluster-name myeks --nodegroup-name myeks-ng-1 | jq아래와 같이 노드 그룹에 대한 메타데이터들 또한 가져올 수 있다.
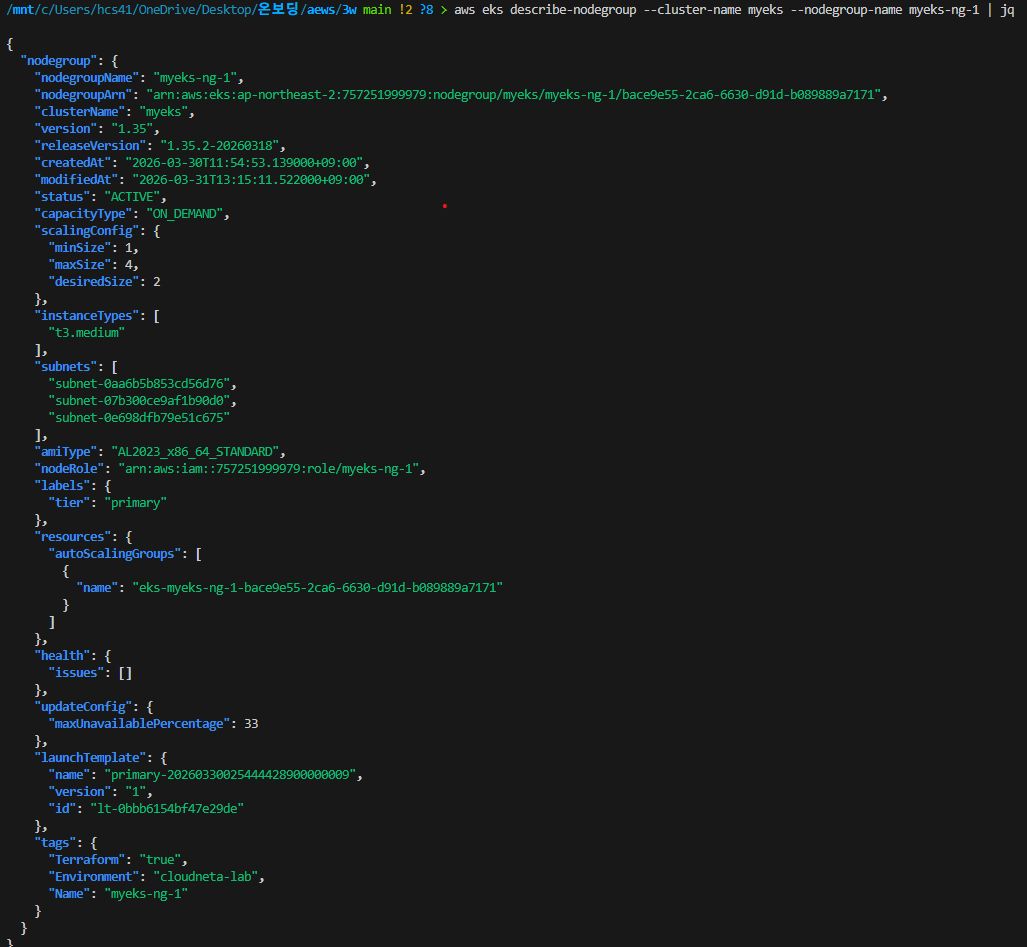
실습에서 2번째 노드그룹을 테라폼으로 배포한 뒤 노드그룹들의 정보를 확인하자.아래 처럼 arm 타입의 새로운 노드가 하나 배포되었음을 확인할 수 있고 노드 그룹이 myeks-ng-2로 설정되어 있는것 또한 확인 가능하다.

추가적으로 노드 그룹 단에서 taints 등의 설정을 통해서 아래 노드처럼 아무런 파드가 배치되지 않도록 설정할 수도 있다. 실제로 파드를 배포해서 아래처럼 잘 동작하는지 한번 확인해보자
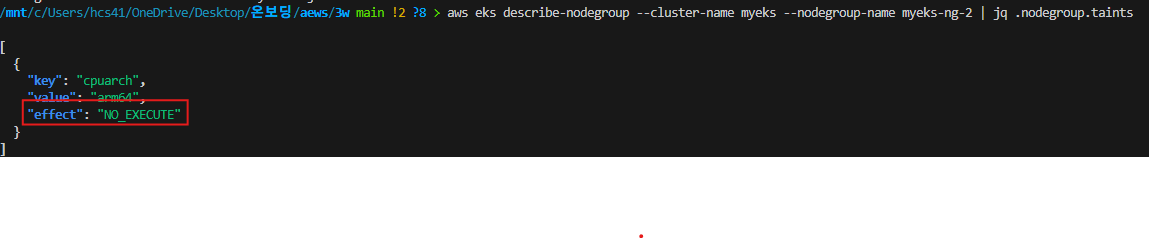
배포한 샘플 앱 파드들은 아래처럼 ARM64에서 구동되도록 설정시켜 둔 상태이다. 그래서 보이는 것 처럼 1 node(node-group-2)는 아예 toleration이 없어서 파드 배치가 안되고 나머지 2 node(node-group-1)는 arm64가 아니기 때문에 애초에 파드 배치가 될 수 가 없다.

NoSchedule vs NoExecute
이 두개의 개념은 k8s taints 및 toleration에 관련된 내용이고, 노드 그룹에 테라폼 등을 통해 이러한 taints 또는 toleration을 적용 시킬 수 있다.
1. NoSchedule (신규 스케줄링 금지)
- 상황: 경호원이 노드 앞에 서서 새롭게 배치될 파드의 toleration(출입증)을 검사한다.
- 특징: 출입증이 없는 새로운 파드는 해당 노드에 스케줄링 될 수 없다. 하지만, 경호원이 문 앞에 서기 전부터 이미 노드 안에서 실행 중이던 기존 파드들은 출입증이 없어도 내쫓기지 않는다. 즉, 기존 작업은 아무런 방해 없이 계속 실행된다.
2. NoExecute (신규 스케줄링 금지 + 기존 파드 즉시 퇴거)
- 상황: 경호원이 방 안으로 들어와 문을 잠그고, 이미 놀고 있는 사람들의 출입증까지 전부 검사하기 시작한다.
- 특징: 만약 평범하게 잘 돌아가며 여러 파드를 품고 있던 노드에 관리자가 갑자기
effect="NoExecute"Taint를 걸어버리면 상황이 완전히 달라진다. - 결과 (즉시 종료 및 퇴거): 쿠버네티스는 즉시 해당 노드에서 돌고 있는 모든 파드를 전수 검사한다. 이때 적절한 toleration(출입증)을 가지고 있지 않은 파드들은 즉시 퇴거조치되어 강제 종료되며, 다른 노드로 짐을 싸서 쫓겨나게(재스케줄링) 된다.
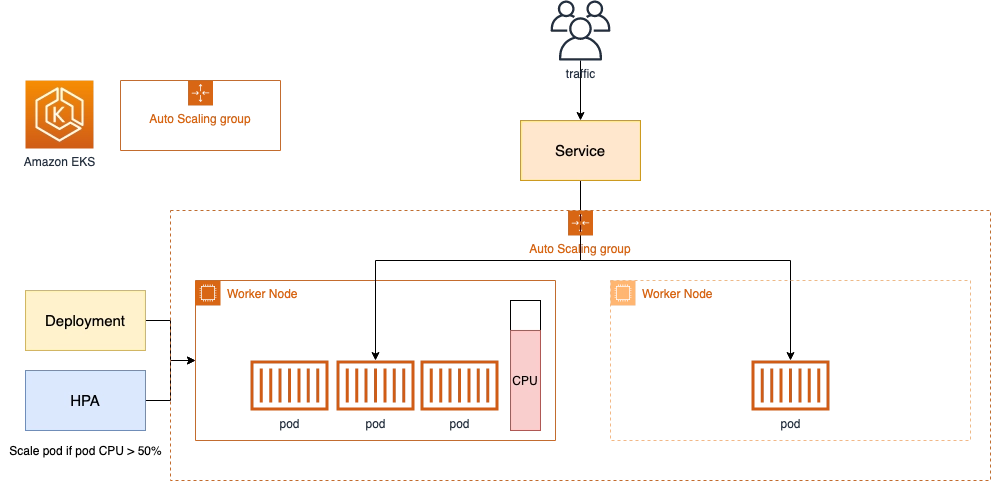
4. EKS Scaling 전략


아래 다이어 그림 및 위 포스팅 기준으로는 크게 4가지 전략을 제안한다.
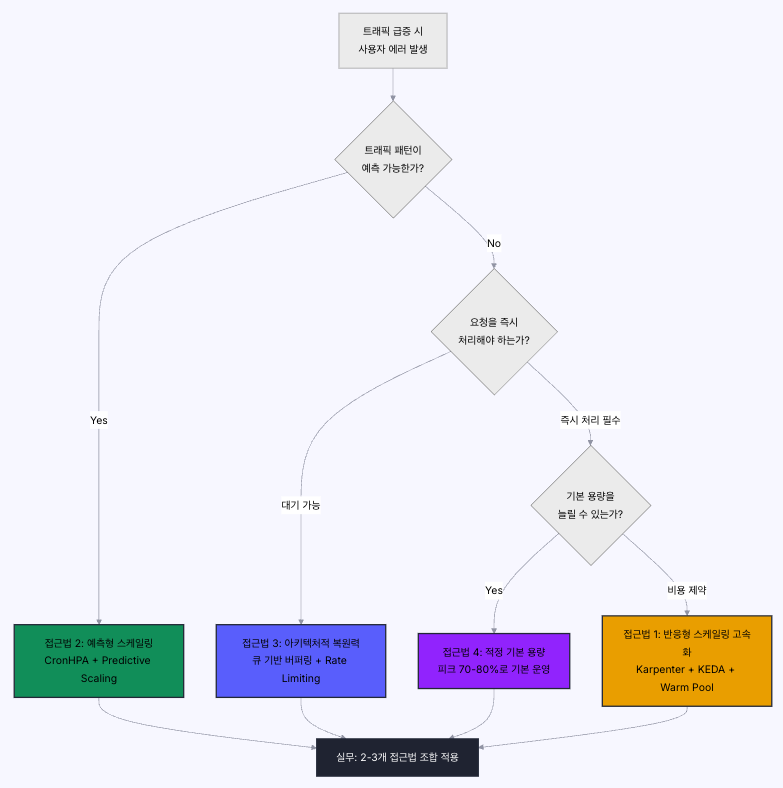
지금 제가 사용하는 패턴은 4번 또는 2번으로 충분히 커버가 되는 상태이다. 그래서 가장 복잡하고 빠르게 스케일링을 처리하는 방식인 4번은 요구사항이 발생하면 그 때 다시 보도록 하자.
5. Horizontal Pod Autoscaler(HPA)

1. 쿠버네티스의 수평 스케일링 자동화: HPA (Horizontal Pod Autoscaler)
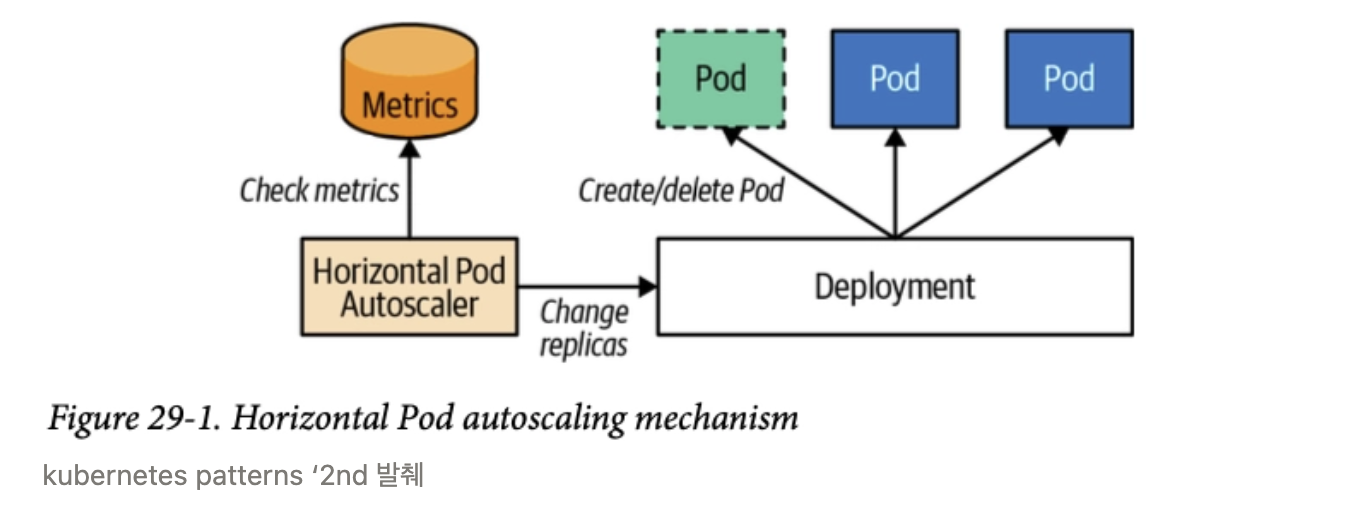
- 쿠버네티스는 트래픽 변화에 맞춰 수평 스케일링을 자동으로 수행해 주는 HPA(Horizontal Pod Autoscaler) 기능을 내장하고 있다.
- HPA는 관리자가 설정한 최소/최대 파드 개수(
minReplicas,maxReplicas) 범위 내에서 동작하며, 파드의 리소스 사용량(주로 CPU나 메모리 메트릭)을 지속적으로 모니터링한다.
2. HPA의 메트릭 기반 동작 원리
- HPA는 현재 실행 중인 모든 파드의 평균 리소스 사용량을 관찰하고, 이를 관리자가 설정한 목표치(Target) 와 일치시키기 위해 파드를 동적으로 생성하거나 제거한다.
동작 예시 (CPU 목표치 20% 설정 시): * 파드들의 평균 CPU 사용률이 목표치인 20%를 초과하면, HPA는 즉시 파드의 복제본 개수를 늘려(Scale-Out) 개별 파드가 받는 부하를 분산시킨다.
- 반대로 트래픽이 줄어들어 평균 CPU 사용률이 20% 밑으로 떨어지면, 불필요한 파드를 제거하여(Scale-In) 리소스를 최적화한다.
3. 안정성을 위한 제어 장치: Cooldown Period
- HPA가 단순히 지표만 보고 파드를 늘리고 줄이기만 한다면, 일시적인 트래픽 튐 현상에 의해 파드가 무의미하게 생성되었다가 즉시 삭제되는 Thrashing 현상이 발생할 수 있다.
- 이를 방지하기 위해 HPA는 Stabilization Window, 즉 재사용 대기 시간이라는 개념을 적용한다. 메트릭 조건이 충족되더라도 일정 시간 동안 추이를 지켜본 뒤 스케일링을 수행함으로써, 클러스터의 불필요한 요동을 방지하고 시스템을 안정적으로 유지한다.
4. HPA는 어디서 실행되고 있을까?
- 많은 사용자들이 HPA가 워커 노드 위에서 데몬셋이나 일반 파드 형태로 실행될 것이라고 오해하지만, 결론부터 말하자면 HPA는 일반적인 파드나 노드에서 실행되는 독립적인 애플리케이션이 아니다.
- 쿠버네티스 공식 문서에 따르면, HPA는 클러스터의 두뇌 역할을 하는 컨트롤 플레인의 핵심 컴포넌트인
kube-controller-manager내부에 하나의 백그라운드 프로세스 형태로 내장되어 동작한다. - 즉, 관리자가
kubectl apply -f hpa.yaml을 통해 HPA 객체를 생성하면, 컨트롤 플레인에 있는kube-controller-manager가 기본적으로 15초(기본값)마다 주기로 활성화되어 파드의 스케일링 필요 여부를 평가하고 API 서버에 명령을 내리는 구조다. - EKS 환경에서의 특징: AWS EKS와 같은 관리형 쿠버네티스 환경에서는 마스터 노드를 AWS가 직접 프로비저닝하고 은닉하여 관리한다. 따라서 사용자의 워커 노드목록이나
kube-system네임스페이스를 아무리 뒤져보아도 HPA 역할을 하는 파드는 보이지 않는 것이 정상이다. - 주의할 점 (메트릭 서버의 위치): HPA 프로세스 자체는 컨트롤 플레인에 숨어 있지만, HPA가 판단을 내리기 위해 파드의 CPU/메모리 지표를 수집해 오는 메트릭 서버(Metrics Server) 는 반드시 사용자의 워커 노드 위에 일반 파드 형태로 배포되어 실행되고 있어야 한다.
HPA의 이론적인 내용은 살펴봤고 실습을 통해 리소스들을 배포해보자.
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
우선 부하의 대상이 되는 파드를 먼저 배포한다. 그리고 나서 부하 넣어주는 파드를 배포한다.
kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 1; done'
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: curl
spec:
containers:
- name: curl
image: curlimages/curl:latest
command: ["sleep", "3600"]
restartPolicy: Never
EOFCPU 사용량을 확인하고 난 뒤, 실제 HPA 리소스를 생성한다.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl describe hpa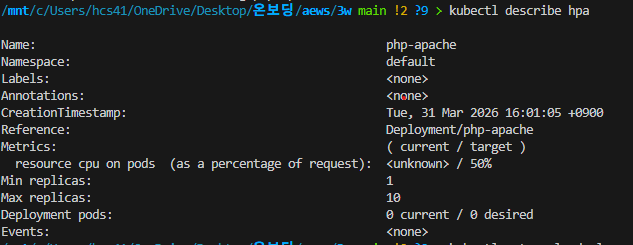
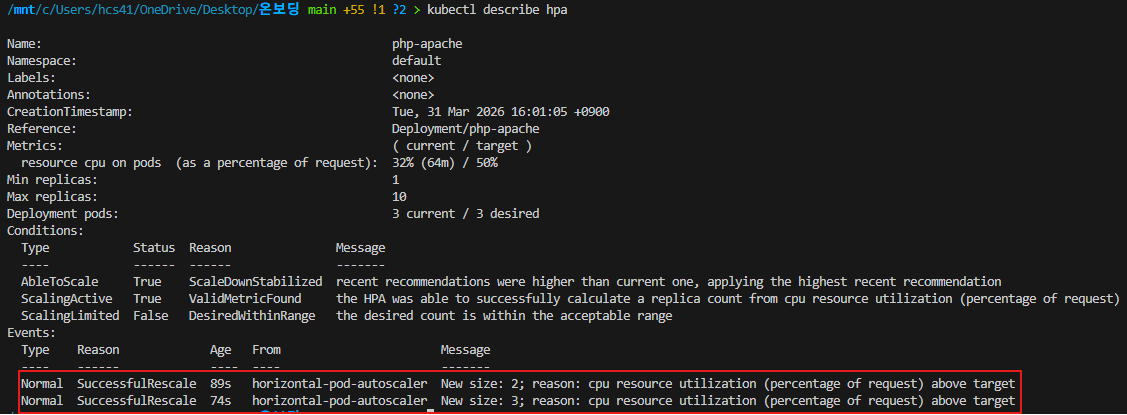
이후 부하를 kubectl exec curl -- sh -c 'while true; do curl -s php-apache; sleep 0.5; done' 를 통해 넣어준다. 아래와 같이 HPA 이벤트를 살펴보면 정상적으로 파드가 늘어난것을 확인할 수 있다.
6. Vertical Pod Autoscaler(VPA)
HPA가 파드의 개수를 조절한다면, VPA는 파드 자체의 **크기(CPU 및 메모리 Requests/Limits)**를 자동으로 조절한다.
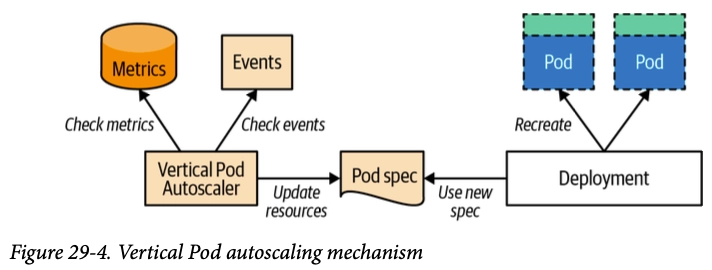
VPA는 HPA와 같이 사용할 수 없고 VPA는 pod자원을 최적값으로 수정하기 위해 pod를 재실행(기존 pod를 종료하고 새로운 pod실행)한다.
7. Cluster Autoscaler
다음으로 살펴볼 기능은 CA이다. 클러스터 내의 워커 노드 개수를 유동적으로 조절하여 가용성 확보와 비용 절감을 위해 사용된다. 클러스터에 배포하려는 파드가 배치될 노드의 리소스(CPU/Mem) 부족으로 인해 파드가 Pending 에 걸리면 이를 감지하고 API를 통해 새로운 워커 노드를 추가한다. 또한 특정 노드의 리소스 사용율이 낮고 해당 노드의 파드들을 다른 노드로 이전 가능하다고 판단되면 해당 노드를 클러스터에서 제외시켜 비용 절감을 달성한다.
또한 추가적으로 중요한 부분은 CA는 노드를 늘려야 할 때, 직접 EC2를 띄우는 것이 아니라 ASG의 'Desired Capacity' 값을 수정해서 동작한다.즉, Managed Node Group에 의해 생성된 ASG을 통해서 각 워커노드의 개수를 조절한다. ASG가 이벤트를 감지한 이후 노드를 프로비저닝하기 때문에 Scale-Out 속도가 느리고 동일한 스펙의 인스턴스 타입만 사용해야한다는 단점이 있다.
CA의 경우 EKS 클러스터를 새롭게 생성해도 자동으로 활성화 되지 않는다. 아래 명령어를 통해 직접 구성해주면 된다.
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i -e "s|<YOUR CLUSTER NAME>|myeks|g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml 헬름 등 구체적인 설치 방식은 아래 참고한다.

설치 후 디플로이먼트를 배포하면 아래처럼 CA 파드가 구동된다.

이제는 노드가 Scale-Out이 잘 되는지 살펴보자. 기존 실습 환경은 두 개의 워커 노드를 가지고 있었다. 파드를 통해 노드에 부하를 가하면 아래처럼 총 2개의 워커 노드가 증가 된 상태를 확인할 수 있다. (NotReady 상태)
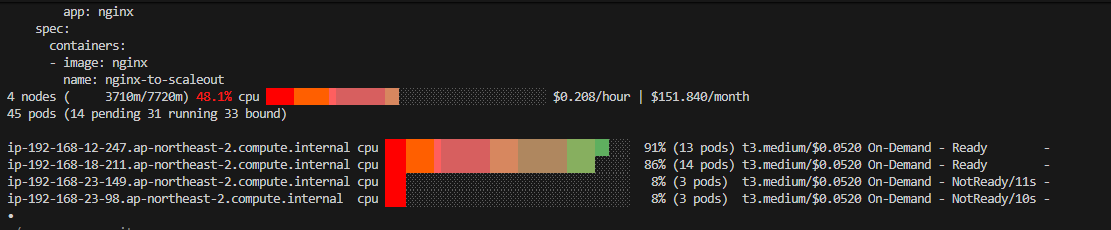
이후 시간이 좀 더 지나면 동일한 t3.medium 타입의 노드가 2개가 추가되어 Ready 상태로 변경되는것을 확인할 수 있다.

대략적으로 부하 발생 후 10분 정도 지나면 다시 사용율이 줄어든것을 감지해서 새롭게 생성된 노드들을 제거해준다.
8. Kapenter
CA의 단점인 ASG 의존성 및 느린 확장 속도를 개선 시켜주는 기술이다.
부하가 없을 때, 현재 클러스터에서는 2개의 노드가 구성된다.

이후 부하를 넣어주게 되면 아래처럼 약 1분 내로 서로 다른 타입의 워커 노드가 조인되면서 확장된다.
업무에서 Kapenter 도입 전 해야 할 실습
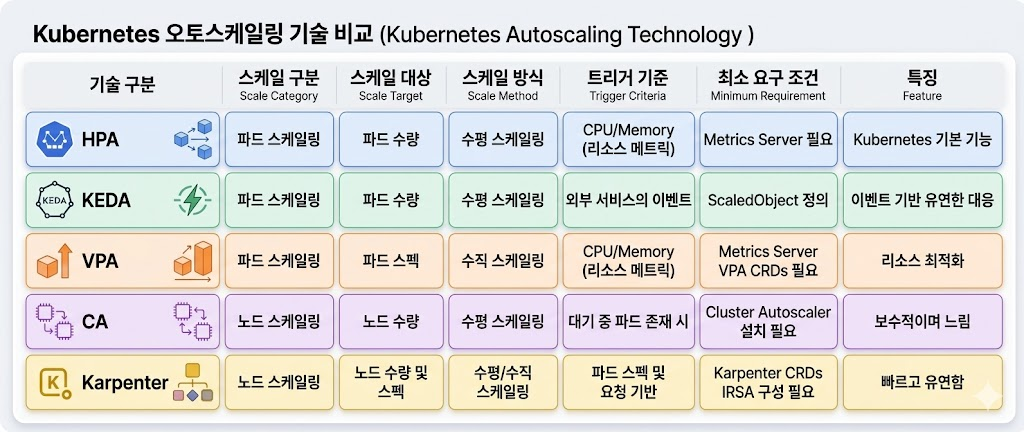
8. Auto-Scaling 기술 비교 (파드 vs 노드)
한눈에 알아보기 쉽게 각 오토 스케일링 기술들을 정리했다.