저번 포스팅까지는 단순하게 메모리라고 함은 dRAM을 가정하고 설명을 진행했습니다.하지만 실제로 컴퓨터에 있는 메모리들의 종류는 다양할뿐더러 계층적으로 존재합니다.우선 컴퓨터의 메모리 구조가 어떻게 아래의 그림과 같은 계층구조를 가지게 되었는지부터 알아봅시다.
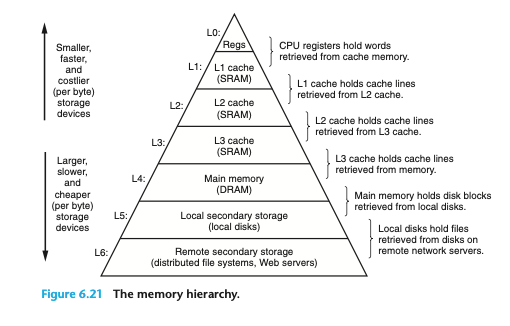
CPU와 메모리간의 차이
CPU는 fetch를 통해 자신이 연산할 명령어와 데이터를 받아옵니다.이후 데이터는 레지스터에 저장하고 이를 기반으로 연산을 수행합니다.이러한 과정은 RAM(메모리)과 데이터를 끊임없이 주고 받음으로서 가능해집니다.
그러나 이러한 방식에 큰 문제점이 존재합니다.이는 바로 CPU가 연산을 수행하는 속도와 RAM이 연산을 수행하는 속도의 편차가 크다는는 것입니다.이러한 현상은 결국 CPU가 본인의 연산을 전부 수행했음에도 다음 명령어를 fetch할 때까지 무작정 기다려야하는 비효율을 초래하게 됩니다.이는 곧,아무리 CPU의 연산능력이 괴물같아도 연산할 대상이 없어서 전체적인 처리 속도가 느려지게 됩니다.
이처럼 RAM의 연산속도가 느리자, 이를 개선시키는 방법을 고민하게 되었고 이는 곧 CPU가 RAM에 접근하는 횟수를 줄이자는 접근을 시도하였습니다.그리고 이러한 생각은 지역성이라는 개념와 직결됩니다.
지역성(Locality)
우선 사전적인 개념은 이번(N+1번)에 접근할 데이터가 저번(N번)에 접근한 데이터와 얼마나 가까이 있느냐에 대한 것입니다.이는 크게 두가지 지역성으로 나눠집니다.
- 시간 지역성
- 공간 지역성
시간 지역성의 경우,어떤 메모리 주소에 접근했을 때 잠시 후에 이와 동일한 주소에 접근할 확률이 높으면 시간 지역성이 좋다고 표현합니다.이와 다르게 공간 지역성의 경우,어떤 메모리 주소에 접근했을때, 잠시 후 그 근처의 메모리 주소에 접근할 확률이 높으면 공간지역성이 좋다고 표현합니다.이름 그대로 ‘시간’과 ‘공간’을 기준으로 다음번 메모리 접근 때 접근할 가능성이 높은 메모리 주소를 지역성이 좋다라고 표현합니다.
직접 예제 코드를 통해 지역성을 구체화 시켜 봅시다.아래 코드들은 2차원 배열의 각 요소들의 총합을 구해주는 함수를 작성한 코드입니다.두 함수의 차이점이 보이시나요?sumArrayRows는 저희가 익숙하게 작성한 것처럼 row(행)을 먼저 접근 후 row에 해당하는 각각의 col(열)들을 통해 배열의 요소에 접근합니다.
int sumArrayRows(int a[M][N]){
int i,j,sum = 0;
for(i = 0; i < M; i++){
for(j = 0; j < N; j++){
sum += a[i][j];
}
}
return sum;
}
반면에 sumArrayCols는 col(열)을 먼저 접근하고 col에 해당하는 row들을 통해 배열의 요소에 접근하고 있습니다.즉,배열의 메모리 구조를 전혀 고려하지 않고 작성한 코드라고 생각하시면 됩니다.조금 더 설명하면,배열 요소들은 int형을 저장할 경우 각각의 주소는 4바이트만큼의 공차를 가지며 주소를 가집니다.즉,가로로 연속된 배열의 요소들은 서로서로 바로 옆(4byte 차이)의 주소를 할당 받게 됩니다.하지만 아래 코드는 배열의 요소들을 세로로 접근을 하기에 나쁜 공간 지역성을 가지는 함수라고 평가할 수 있습니다.
int sumArrayCols(int a[M][N]){
int i,j,sum = 0;
for(j = 0; j < N; i++){
for(i = 0; i < M; j++){
sum += a[i][j];
}
}
return sum;
}
그러면 이러한 지역성을 어떻게 활용해야 CPU 연산의 효율을 높일 수 있었을까요? 컴파일된 코드의 지역성을 분석해 조만간 접근할 가능성이 높은 메모리 주소들을 미리 예측하고, 그 주소에 존재하는 데이터들을 CPU의 레지스터에 미리 저장하면 CPU가 메모리에 자주 접근하지 않아도 되니 CPU의 RAM 접근 연산 횟수를 비약적으로 줄일 수 있습니다.하지만 다들 아시다시피 레지스터는 CPU내의 조그마한 메모리이고 용량이 굉장히 작습니다.그리고 이러한 레지스터의 용량을 늘리기 위해서는 비용적인 문제가 큽니다.이러한 단점을 해결하기 위해 등장한것이 캐시입니다.
캐시(Cache)
앞서 말씀드린것처럼 레지스터의 용량을 늘리지 못하니 이에 대한 해결책으로 캐시가 등장합니다.캐시에 대한 정의를 하자면 보다 크고 느린 메모리에 저장된 데이터를 위한 준비 영역으로 사용하는 작고 빠른 저장장치입니다.그래서 고안된 첫번째 캐시의 형태는 레지스터처럼 CPU 내의 보조 메모리 장치의 역할을 수행합니다.이가 바로 아래 그림에 보이는 L1캐시입니다. 다양한 캐시들 중 속도가 가장 빠르지만 그만큼 용량이 작다는 단점이 존재합니다.결국 똑같은 문제에 직면한 컴퓨터 과학자들은 L1캐시의 캐시를 만들기로 합니다.그 결과가 바로 L2 캐시입니다.이런식으로 캐시 메모리들은 계층을 통해 서로가 서로의 캐시 역할을 하며 CPU의 효율성을 증가시켰습니다.
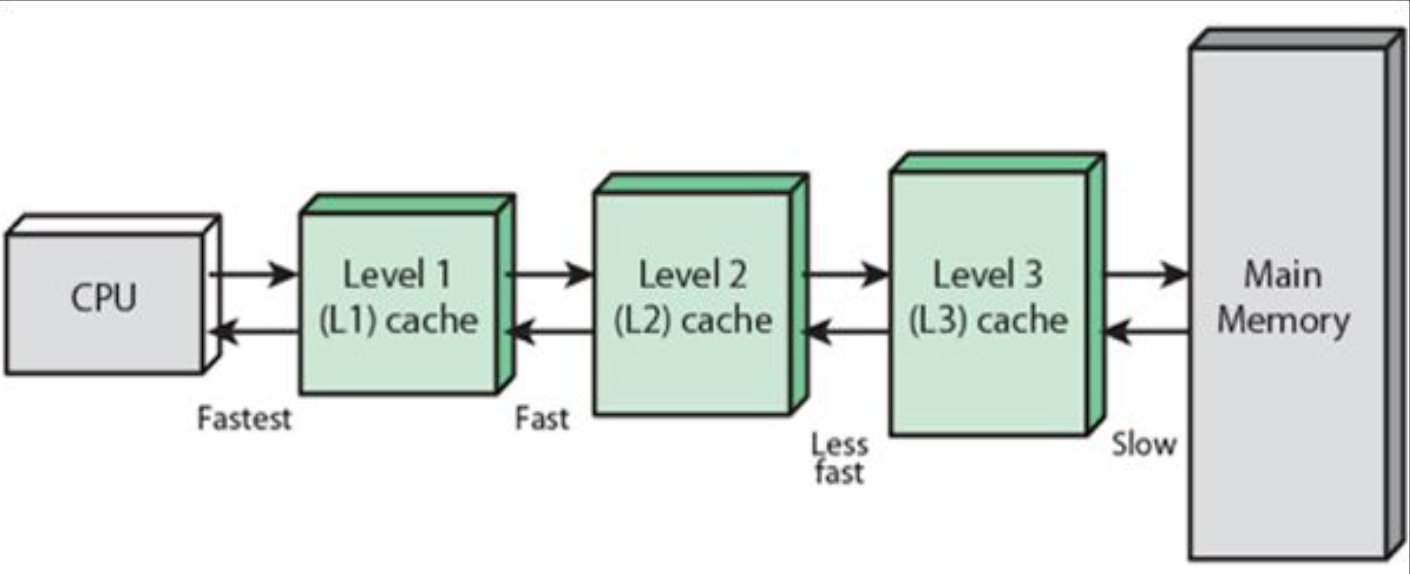
정리해보겠습니다.접근 가능성이 높은 메모리의 주소의 데이터들을 캐시에 저장을 해두고 CPU가 메모리에 직접 접근 하지 않아도 자주 쓰이는 주소의 값을 빠르게 가져올 수 있습니다.좀 더 구체적으로 보면 가장 자주 쓰일 가능성이 높은 데이터는 L1 캐시에 그 다음의 가능성을 가지는 데이터들은 L2, 그 다음은 L3에 저장하며 계층적으로 CPU의 연산 속도를 보완하여 줍니다.또한 레지스터와 L1간 데이터 전송을 할때는 워드(4Byte) 크기만큼의 블록을 사용하고 L1과 L2 사이의 데이터 전송은 수십 바이트 단위의 블록 사용합니다.즉,계층이 내려갈수록 접근 시간이 길어지기에 이를 보완하기위해 큰 용량의 데이터 블록을 사용합니다.
(참고로 일반적인 형태로 L1,L2는 CPU 내부에,L3는 외부에 존재합니다)
캐시 적중률
저희가 앞서 지역성에 대해 배워보았는데 이러한 지역성은 소프트웨어 개발자가 코드를 통해 신경써야하는 부분도 맞지만 동시에 CPU를 설계할 경우에 신경 써야하는 부분이기도 합니다.왜냐하면 결국 CPU가 가진 특성 때문에 지역성이라는 개념이 생겼기 때문입니다.
CPU가 메모리에 접근할 때는 아래와 같은 두가지 경향이 존재합니다.
- CPU가 최근에 접근했던 메모리 공간에 다시 접근하려는 경향
- CPU가 접근한 메모리 주소의 근처를 접근하려는 경향
위의 CPU의 두가지 경향이 앞서 배운 시간적,공간적 지역성과 동일한 것이 이해가 가시나요?반복하자면 지역성이라는 개념 또한 CPU가 메모리에 접근하는 경향을 바탕으로 만들어진 원리입니다.
그러면 이러한 CPU가 지역성을 통해 자주 쓰일것 같은 주소의 값을 캐시에 넣어두었다고 생각해봅시다.여기서 그 다음번 연산에서 해당 캐시에 존재하는 값을 사용을 하면 캐시 히트라고 표현하고 만약 사용하지 않았을 경우는 캐시 미스라고 표현합니다.
위의 두가지 수치를 통해 CPU 캐시 성능을 확인해주는 지표가 캐시 적중률입니다. 아래의 간단한 수식을 통해 계산 가능합니다.
캐시 적중률 = (캐시 히트 횟수 / 캐시 히트 횟수 + 캐시 미스 횟수)
즉,CPU는 캐시 적중률을 높여야만 효율적인 연산 속도를 가질 수 있습니다.(참고로 요즘 CPU들의 적중률은 대부분 80% 이상이라고 합니다)
이렇게 해서 CPU가 메모리에 접근하는 횟수를 줄여 CPU가 온전한 연산속도를 가지도록 하는 방법인 캐시 메모리에 대해 알아보았습니다.