이번 포스팅에서는 Java Reactive Streams이 어떤 요구사항에 의해 생겼는지 그리고Publisher와 Subscriber의 기본적인 동작에 대해서 작성할 예정입니다.
Iterable vs Observable
Project Reactor의 공식문서에서 Reactive stream와 Iterable-Iterator의 경우 daulity(쌍대성)를 갖는다고 얘기합니다. 여기서 말하는 쌍대성이란 동일한 동작을 수행하지만 서로 반대되는 방식으로 해당 동작을 수행하는 할 경우, 쌍대성을 갖는다라고 이해할 수 있습니다. 그러면 Reactive stream의 모태가 되는 Observer 패턴 또한 Iterable-Iterator와 동일하게 쌍대성을 가지는지 한번 확인해보겠습니다.
먼저 Iterator를 먼저 살펴보면 for loop을 통해서 Iterator 내의 요소들을 순회하면서 해당 데이터를 가져와서 사용할 수 있습니다. 여기서 중요한것은 데이터를 끌어온다는 점이죠. List를 생성하는 대신 아래와 같이 직접 구현해서 만들 수 있습니다.
@Test
void iterater(){
Iterable<Integer> iter = () -> new Iterator<>() {
//원소를 모두 나열하지 않고 1 ~ 10 까지 순회하는 법
int i = 0;
final static int MAX = 10;
@Override
public boolean hasNext() {
return i < MAX;
}
@Override
public Integer next() {
return i += 1;
}
};
for (Integer i : iter) { //for-each
System.out.println(i);
}
}
반대로 Observer와 Observable을 살펴보면, Observable에서 사용자가 사용해야하는 데이터를 넣어주고, 이를 Observer에서 사용할 수 있습니다. 데이터를 한쪽에서 밀어주는 방식인거죠. Observable -> Observer 방향으로 데이터를 밀어주고 있습니다.
@Test
void observer(){
Observer observer = new Observer() { // 데이터 받는 수신 쪽, 소비자
// notifyObservers 할 경우 아래 Update 메서드 호출됨
@Override
public void update(Observable o, Object arg) {
System.out.println("Observer.update");;
System.out.println(arg);
}
};
IntObservable intObservable = new IntObservable();
intObservable.addObserver(observer); //event-driven에서 대표적으로 활용되는 패턴
intObservable.run();
}
private static class IntObservable extends Observable implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 10; i++) {
setChanged();
notifyObservers(i); // push 하는 동작 iter.next()에 대응되는 로직
}
}
}
하지만 두 방식 모두 가져온 데이터를 사용할 수 있도록 하는 방식임은 동일합니다. 즉, 해당 데이터를 어떻게 가져온것인지가 서로 반대될 뿐이고 데이터를 사용한다는 최종적인 동작은 다르지 않습니다.
Observable 의 한계?
앞서 언급되었듯이 Reactive Streams의 모태가 되는 패턴이 Observer 패턴입니다.그러면 어떤 요구사항 때문에 Reactive Streams가 발생하였을까요?
- 데이터를 전부 보내고 나서 완료 처리 불가
- 데이터를 전송하는 중 예외 발생 시 복구 처리 불가
앞선 Obersverable의 예시 코드를 살펴보아도 데이터를 전부 보내고 나서도 어떠한 완료 등의 시그널을 Obersverable을 통해서 설정 할 수는 없었습니다. 물론 CountDownLatch 등으로 Observer 쪽에서 데이터를 수신 완료한 경우 처리를 해줄 수는 있겠죠.하지만 이 또한 데이터 전송 과정에서 예외가 발생하면 로직이 복잡해질 것입니다.
그래서 이와 같은 단점을 해결하기 위해 Reactive Streams은 위 두가지 기능이 제공되는 Observer 패턴을 제공한다라고 이해하실 수 있습니다.
Reactive Streams의 구현체
본격적인 Reactive Streams의 내용을 보기전에 Reactive Streams를 제공하는 다양한 구현체들에 대해서 간단히 정리하고 넘어가겠습니다. Reactive Streams는 표준이라고 보시면 됩니다. 그리고 이러한 표준을 구현한 것들이 RxJava, Project Reactor 등등이 존재합니다. (JPA - Hibernate의 관계) 그리고 잘 알려진 Spring Web-Flux의 경우 Project Reactor를 기반으로 구축된 스프링 프레임워크의 일부라고 이해할 수 있습니다.
Publisher, Subscriber, Subscription
지금부터는 본격적으로 Reactive Streams에서 제공하는 아래의 3가지 인터페이스들 간의 관계와 표준 프로토콜 흐름을 알아보겠습니다. 우선 소개할 인터페이스들은 아래와 같습니다.
@FunctionalInterface
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> subscriber);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription subscription);
public void onNext(T item);
public void onError(Throwable throwable);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}
Observer 패턴의 문제를 해결하기 위해 위와 같은 3가지의 인터페이스가 도입되었습니다.그러면 Observer와 Observable에 대응되는 각각의 인터페이스가 존재합니다. 아래와 같습니다.
- Observer <-> Subscriber
- Observable <-> Publisher
대략적으로 Publiser가 데이터를 밀어주는 역할을 수행하고, Subscriber가 데이터를 받는 역할을 수행한다고 볼 수 있습니다. 그리고 둘 사이의 연결 자체를 Subscription이라합니다.
앞선 예제에서 intObservable.addObserver(observer)를 수행한것처럼 publisher.subscribe(Subscriber)를 수행하며 Reactive-stream의 프로토콜은 시작됩니다. 즉, 이들간의 이벤트 또는 데이터 전송은 정해진 프로토콜에서 정의한 순서대로 지정된 메서드를 호출하며 이루어집니다.
Reactive Streams의 표준 프로토콜
표준 프로토콜은 아래와 같습니다. 이는 publisher.subscribe가 호출되고 나서 발생해야하는 함수호출의 시퀀스를 나타내고 있습니다. 가장 먼저 onSubscribe를 호출하고 나서 onNext를 0번 또는 n번 호출한 다음, 마지막으로 데이터 전송의 완료를 onError 또는 onComplete를 호출하여 처리합니다.
onSubscribe onNext* (onError | onComplete)
이를 그림으로 간단히 나타내면 아래와 같습니다.
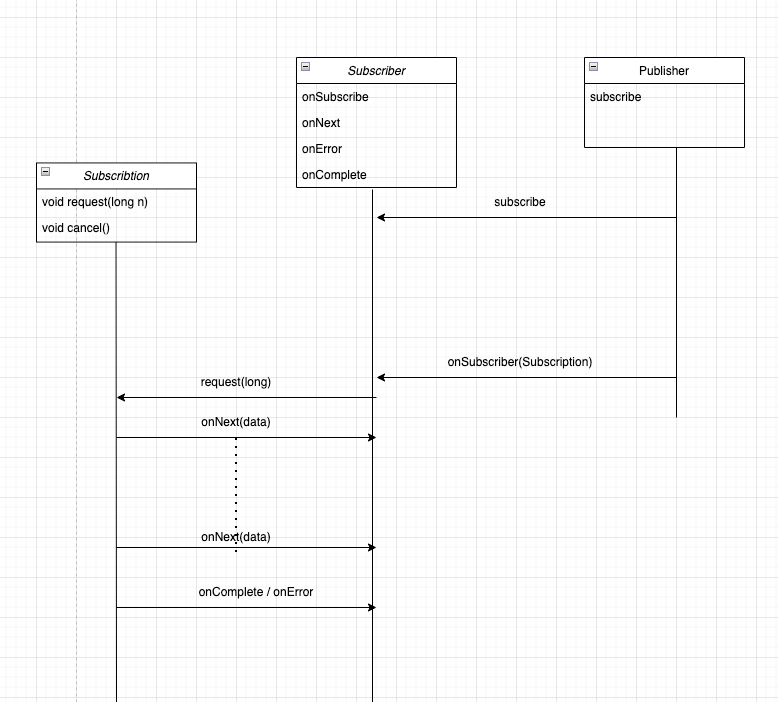
Publisher에 Subscriber를 등록하고나서, Publisher는 처음으로 onSubscribe를 호출하면 그 인자로 Subscription 인스턴스를 전달합니다. 이후 Subcriber는 자신이 받을 수 있는 데이터의 양을 알려주기 위해 request를 호출합니다. 만약 한번의 request로 Publisher가 가진 모든 데이터를 받아올 경우, 곧바로 request 내에서 onComplete 또는 onError로 데이터 전송을 끝내고, 반면 데이터가 남아있을 경우는 onNext()를 통해 남은 데이터를 계속 받을 수 있습니다.
Subscription 내에는 이후 Subscriber가 호출할 콜백 메서드인 request, cancel이 구현되어 있습니다. request는 Subscriber가 Publisher에게 넘겨준 인자의 개수만큼 데이터를 처리할 준비가 되어 있음을 알릴 수 있습니다. 두 번째 메서드인 cancel은 예외적인 상황에서 Subscription을 취소, 즉 더 이상 데이터를 받을 수 없음을 알려줄 수 있습니다.
Publisher와Subscriber 의 사용예시를 직접 코드를 보면서 이해해보겠습니다.
List<T> 타입을 인자로 받는 ListPublisher는 내부적으로 인자로 들어온 리스트를 Iterator로 변환시켜줍니다. 그리고 이러한 Publisher를 구독하는 MySubscriber는 request(int)에 넘겨진 int 값만큼 리스트의 원소를 Iterator로부터 받아옵니다. 받아온 후 이를 간단히 출력해주는 역할을 수행합니다.
public class MySubscriber<T> implements Subscriber<T> {
private Subscription subscription;
@Override
public void onSubscribe(Subscription s) {
System.out.println("MySubscriber.onSubscribe");
this.subscription = s;
s.request(1);
}
@Override
public void onNext(T t) {
System.out.println("OnNext item = " + t);
subscription.request(1);
}
@Override
public void onError(Throwable t) {
System.out.println("t.getCause() = " + t.getCause());
}
@Override
public void onComplete() {
System.out.println("MySubscriber.onComplete");
}
}
public class ListPublisher<T> implements Publisher<T> {
private final Iterator<T> list;
public ListPublisher(List<T> list) {
this.list = list.iterator();
}
@Override
public void subscribe(Subscriber<? super T> s) {
s.onSubscribe(new Subscription() {
@Override
public void request(long n) {
int i = 0;
try {
while (i++ < n) {
if (list.hasNext()) {
s.onNext(list.next());
} else {
s.onComplete();
break;
}
}
} catch (RuntimeException e) {
s.onError(e);
}
}
@Override
public void cancel() {
}
});
}
}
위 둘간의 데이터 교환을 발생시키는 메인 메서드는 아래와 같이 구성하면 됩니다.
public class Main {
public static void main(String[] args) {
List<Double> lists = List.of(1.0, 1.1, 1.2, .13);
ListPublisher<Double> publisher = new ListPublisher<>(lists);
publisher.subscribe(new MySubscriber<>());
}
}
프로토콜의 순서대로 차근차근 따라가보겠습니다.
- 먼저 생성한 lists 변수를
Publisher생성자의 인자로 하여Publisher인스턴스를 생성합니다. 이후publisher.subscribe를 호출하여 표준 프로토콜의 시작을 알립니다. 호출과 동시에Subscriber인스턴스를 onSubscribe 메서드의 인자로 넘겨줍니다. -> Publisher.subscribe(Subscriber) 호출 Publisher의 subscribe 메서드 구현 내부에는 인자로 들어온Subscriber인스턴스의 onSubscribe 메서드를 곧바로 호출시킵니다. 호출과 동시에Subscription인스턴스를 메서드의 인자로 넘겨주면서Subscriber가 호출할 콜백 메서드들을 구현해줍니다. -> subscriber.onSubscribe(Subscription) 호출- onSubscribe 메서드 내부 구현은
MySubscriber에 존재하며, 메서드 출력을 한번 하고 나서 subscription 변수를 주입해주고s.request(1)을 통해 한개의 데이터를 받을 준비가 되었음을 알려줍니다. request() 메서드는Subscriber가 데이터를 받아 처리할 수 있음을 역압력을 통해Publisher에게 알리도록 해줍니다. - ListPublisher 내의 request() 로직 내에서 Iterator에 데이터가 남아있으면 onNext()를 호출하고 전부 다 Subscriber에게 전달하였을 경우엔 onComplete를 호출합니다. 만약 예외가 발생할 경우는 onError를 호출합니다.
- 만약 데이터가 남아 onNext()가 호출된 경우 다시 한번
Subscriber가 requset()를 호출해 남아있는 데이터를Publisher에게 요청합니다.
이러한 함수 호출 시퀀스를 통해 Publisher와 Subscriber는 데이터 스트림 처리와 역압을 관리합니다.
이번 포스팅에서는 Publisher와 Subscriber 간의 데이터를 주고 받는 방식과 아주 간단한 예제를 통해 어떻게 이러한 동작들이 구현되는지 코드로 알아보았습니다.