본 포스팅에서는 Java에서 제공하는 스레드 풀의 내부 동작에 대해서 다룹니다. “단순히 요청이 오면 Idle한 스레드가 수행한다” 정도는 아니고 스레드 풀 내부의 큐 구현에 따라 어떻게 동작이 달라지는지 스레드 풀의 스레드 개수는 언제 증가하는지 등의 세부적인 동작에 대해 알아볼 예정입니다.
스레드풀과 큐
Java에서 제공하는 스레드풀은 기본적으로 내부에 작업 큐를 가진다.이러한 작업 큐를 통해 생산자-소비자 패턴을 구현할 수 있다.간략히 그림으로 나타내면 아래와 같다.
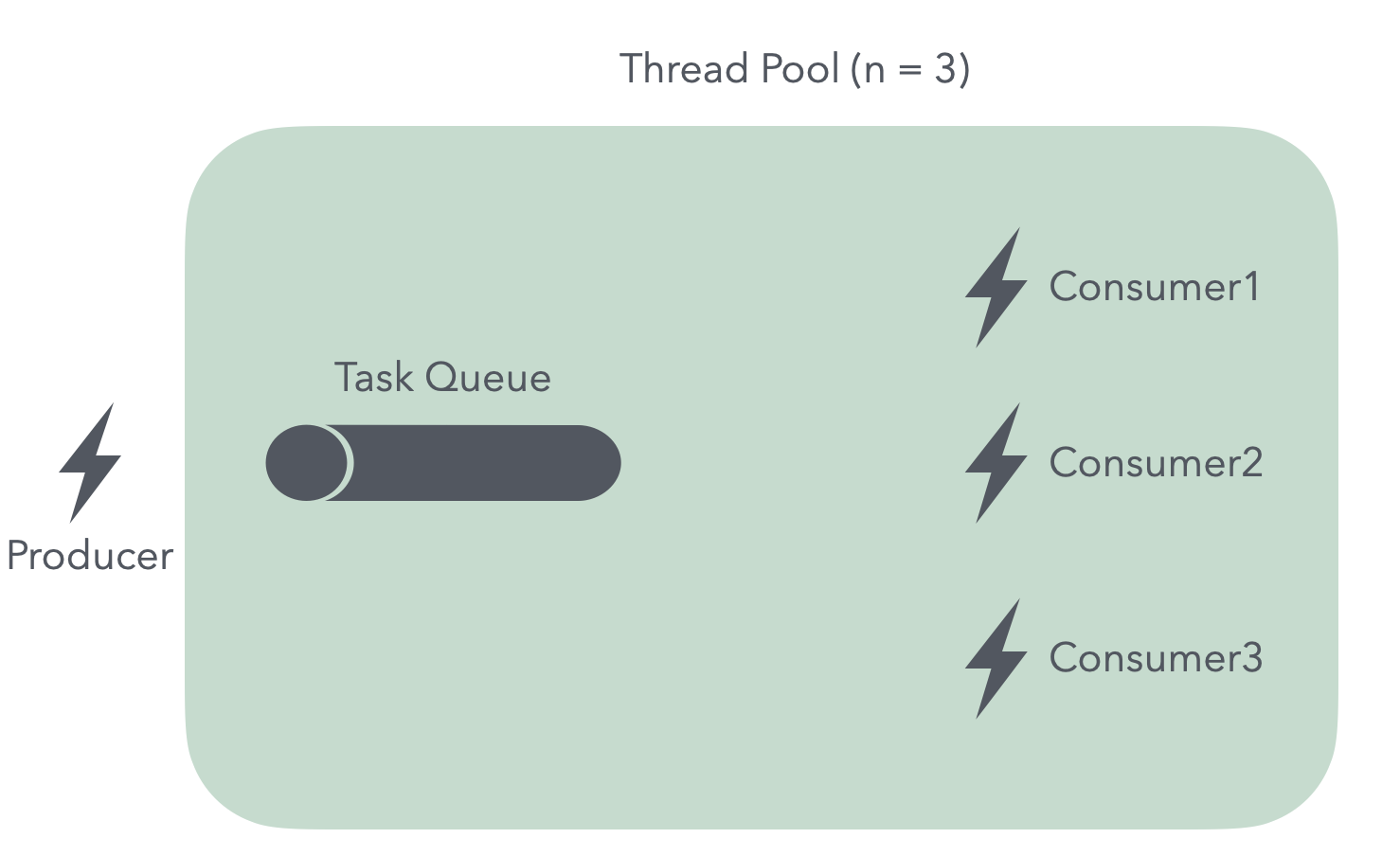
작업 큐는 내부적으로 BlockingQueue의 구현체를 사용한다.큐 구현체가 어떤 종류인지에 따라 스레드풀의 동작이 달라지는 부분이 있다. 구현체들에 대한 특징과 내부 동작을 알아보기 전에 BlockingQueue라는 인터페이스에 대해서 먼저 알아보자.
Blocking Queue
JavaDoc에서 Blocking Queue가 제공하는 메서드를 정리한 표를 살펴보자.크게 3가지 기능을 수행하는 메서드들이 그 동작을 어떻게 수행하는지에 따라 3가지로 나뉜다.
먼저 Throws Exception을 먼저 살펴보면 해당 동작이 실패할 경우 예외를 던진다.만약 add(e)를 수행하려는 큐에 공간이 없다면 해당 메서드는 IllegalStateException을 발생시켜 사용자에게 알려준다. Special Value라는 동작은 메서드가 정상 동작하지 않을 경우 null이나 false를 발생시켜 사용자에게 알려주는 메서드이다. 마지막으로 Blocks통해 동작을 수행한다는 것은 put 또는 take을 요청한 메서드는 정상적으로 해당 동작을 수행할 수 있을 때까지 대기하여 동작한다. 즉 put의 경우 큐 내부에 공간이 없으면 생길 때까지 해당 스레드가 대기하고 take의 경우 큐 내부에 작업이 없을 경우 작업이 들어와서 가져갈 수 있을 때까지 대기한다.
| Behavior | Throws Exception | Special Value | Blocks |
|---|---|---|---|
| Insert | add(e) | offer(e) | put(e) |
| Remove | remove() | poll() | take() |
| Examine | element() | peek() | X |
이 외 추가적으로 무한정 Block되지 않고 일정한 timeout을 두고 공간 또는 요소가 생기기를 기다리는 메서드도 제공한다. 결론적으로 스레드가 블락킹 되는 기능을 큐에서 제공하여 생산자-소비자 패턴을 구현할 수 있도록 한다.
다음으로 이러한 인터페이스의 대표적인 3가지 구현체를 살펴보자.
- LinkedBlockingQueue
- ArrayBlockingQueue
- SynchronousQueue
각각의 특징을 먼저 살펴보자. LinkedBlockingQueue는 생성자에 인자를 전달하지 않을 경우 Integer.MAX_VALUE 크기만큼의 설정된다. 생성자에 인자로 큐의 사이즈를 설정해 줄 수도 있다. 반면 ArrayBlockingQueue는 배열 기반의 구현체답게 생성자에 해당 큐의 크기를 항상 설정해줘야한다. 이 둘 구현체는 큐의 크기를 설정할 수 있는 특징을 가진다.
이와 반대로 SynchronousQueue는 큐의 크기라는 개념이 존재하지 않는다.즉, 작업을 담아두는 용도의 자료구조가 아니라 생산자가 소비자에게 작업을 전달하기 위해 존재하는 자료구조이다. 사실 이 개념을 처음 접하는 독자들을 헷갈릴 수도 있다. 간단한 예제 코드를 통해 알아보자.
10개의 수를 큐에 넣는 로직이다. 아래를 그대로 실행시키면 예외가 발생된다. sync라는 큐에 0이라는 값을 넣고나서 해당 값이 소모되기 전에 또 다른 값을 넣으려고 시도하여서 예외가 발생하는 것이다. 반면 array와 linked 큐는 정상적으로 10개의 값을 큐에 삽입 시킬 수 있다. 결론적으로 SynchronousQueue는 하나의 작업(값)을 다른 스레드에게 전달하만 하는 목적으로 사용된다. (문서에서는 hand-off 라는 표현 사용)
private static int SIZE = 10;
public static void main(String[] args) {
BlockingQueue<Integer> sync = new SynchronousQueue<>();
BlockingQueue<Integer> array = new ArrayBlockingQueue<>(SIZE);
BlockingQueue<Integer> linked = new LinkedBlockingQueue<>();
for (int i = 0; i < 10; i++) {
//sync.add(i);
array.add(i);
linked.add(i);
}
}
다음으로는 이러한 큐를 통해 어떠한 종류의 스레드풀을 구현할 수 있고 내부 스레드 생성 동작이 어떻게 구현되었는지 살펴보자.
스레드 생성에 대한 오해
스레드풀은 언제 스레드를 생성할까? 보통 아래 두가지 경우를 떠올린다.
- 현재 존재하는 모든 스레드가 busy한 상태에서 작업이 들어올 때
- 내부 큐가 가득차서 더 이상 작업을 받을 수 없을 때
공식 문서에는 이를 다음과 같이 알려준다. 스레드 풀의 coreThreadSize 수보다 적은 수의 스레드가 존재할 때는 작업이 들어올 때 마다 coreThreadSize만큼의 스레드를 생성한다. 그럴면 coreThreadSize 만큼의 스레드가 보장된 상황에서는 어떨까? 이 때는 큐의 크기에 따라 결정된다. 만약 큐의 크기가 가득 찬 상태일 경우에는 새로운 스레드 생성해서 들어오는 작업을 맡긴다. 반면 큐에 여유 공간이 있을 때는 현재 스레드풀에 idle한 스레드가 없더라도 스레드를 새롭게 생성하지 않는다. 이러한 케이스를 코드를 살펴보자.
public class QueueTest {
public static void main(String[] args) {
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 5, 10, TimeUnit.MINUTES, new ArrayBlockingQueue<>(20));
for (int i = 0; i < 10; i++) {
threadPool.execute(() -> {
try {
System.out.println("threadPool.getPoolSize() = " + threadPool.getPoolSize());
System.out.println("threadPool.getQueue().size() = " + threadPool.getQueue().size());
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
System.out.println("execute done.");
threadPool.shutdown();
}
}
위 코드를 실행 시키면 아래와 같이 main 스레드에 의한 10개의 작업이 먼저 큐에 삽입된다.이후 Task에 의해 현재 스레드풀의 크기와 현재 큐의 크기가 출력된다. 스레드풀의 크기를 확인해보면 1로 고정되어 하나의 스레드만이 삽입된 10개의 작업을 수행한다.즉, 총 10초 가량의 시간이 소요된다.
그러면 여기서 스레드풀 큐의 크기를 5로 줄여보자. 2초만에 작업이 완료되고 스레드가 5개까지 생성되는것을 볼 수 있다. 왜그런지 살펴보자.
- 크기가 5인 큐에 처음에 순서대로 10개의 작업 삽입
- 1번작업은 core에 해당하는 스레드에 수행 (스레드수 : 1)
- 2,3,4,5,6은 큐에 대기
- 7번 삽입할 경우 큐가 가득 차서 스레드 생성 (스레드 수 : 2)
- 생성된 스레드가 FIFO로 앞선 작업 수행
- 8,9,10 작업을 넣을 때 모두 큐가 가득 찼기에 스레드 생성 (스레드 수 : 5)
큐가 가득찼을 경우에만 스레드를 생성하기에 풀 사이즈가 5로 나오는것을 확인할 수 있다.
지금까지는 스레드풀의 내부 큐를 적절한 크기로 설정한 경우를 살펴보았다. 다음으로는 큐의 크기를 INTEGER.MAX_VALUE로 설정하거나 내부 큐를 SynchronousQueue로 설정하는 경우를 살펴보자.
아래 두 메서드는 Executors 클래스에서 제공하는 스태틱 메서드들이다. 각각 스레드풀인스턴스를 리턴해주는 메서드이다. newFixedThreadPool의 경우 고정된 크기의 스레드풀을 가지도록 구현해야한다. 즉,큐 내부에 작업이 쌓이지 않도록 구현되어야 한다. 그러기 위해서 우선 core, max 스레드 수를 같게 하고 생성자가 없는 LinkedBlockingQueue를 사용함으로써 최대 개수만큼의 작업을 저장하도록 한다. nThreads에 의해 스레드수가 동일하게 유지되더라도 큐의 크기가 작게 설정되면 큐에 작업이 쌓이지 못하기 때문에 RejectedExecutionException 가 발생하여 작업실행 자체가 거부된다. 그래서 최대 크기의 큐를 통해 거부 확률을 낮춰준다. (참고로 LinkedBlockingQueue의 생성자 인자를 생략하면 Integer.MAX_VALUE로 크기가 설정된다)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
다음으로는 cachedThreadPool을 살펴보자. 이는 내부적으로 SynchronousQueue를 사용한다. 즉, 큐의 크기가 존재하지 않는다. 그래서 큐에 작업이 다른 스레드에 의해 take 되지 않은 경우 그 즉시 새로운 스레드를 생성하여 스레드풀의 크기를 늘려준다. 스레드 풀의 개수를 감소시키기 위해서는 다음과 같은 전략을 취한다. 특정시간만큼 스레드가 idle한 경우, 해당 스레드를 제거하여 스레드풀의 크기를 조절한다.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
이렇게 자바에서 제공하는 스레드풀의 내부 동작원리와 구현을 살펴보았다.
Reference
- https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ThreadPoolExecutor.html