본 포스팅은 여러개의 주제로 구성되어 스프링부트 환경에서 DataSource로의 요청을 분산시키는 여러 방법들에 대해서 알아볼 예정입니다. DataSource 분산 처리는 아래의 두 가지 주제로 구성될 예정입니다.
@Trnasactional의 readOnly 값에 의한 DataSource 분산 처리- 샤딩 기법에 의한 DataSource 분산 처리 (mod, range, constant-hash)
첫번째 포스팅의 주제로 @Trnasactional의 readOnly값이 true인 경우와 false인 경우에 따라서 요청을 보내는 DataSource를 서로 다르게 설정하는 방법을 알아보겠습니다.
Replication
본 포스팅을 이해하는 데 있어 필요한 개념은 DB Replication이다. 레플리케이션 이중화를 도식화하면 대략 아래의 구조를 취한다.
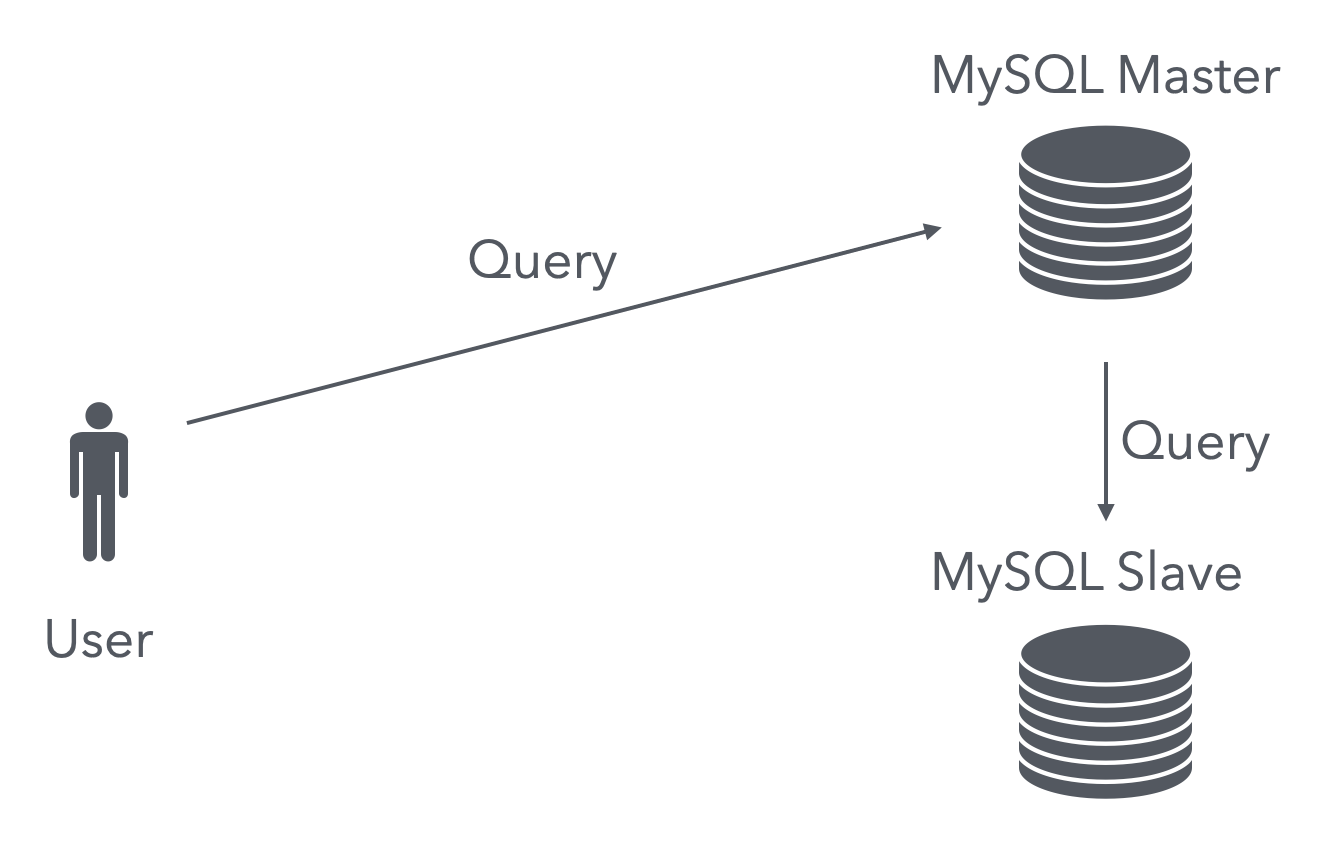
사용자가 전송한 쿼리가 master 노드에 먼저 기록이 되고 이후 slave 노드에 해당 쿼리를 적용시켜 두 노드 간의 데이터 정합성을 맞춰주려 한다. 하지만 두 노드간에 저장되는 DML 연산이 원자적으로 이뤄지지는 않아서 짧은 순간에는 데이터 정합성이 깨질수도 있다. (참고)
이번 포스팅에서도 위와 같은 복제 환경을 기본으로 사용한다.
위 그림과 함께 스프링부트 WAS를 추가한 설계는 아래와 같이 구성될 수 있다.
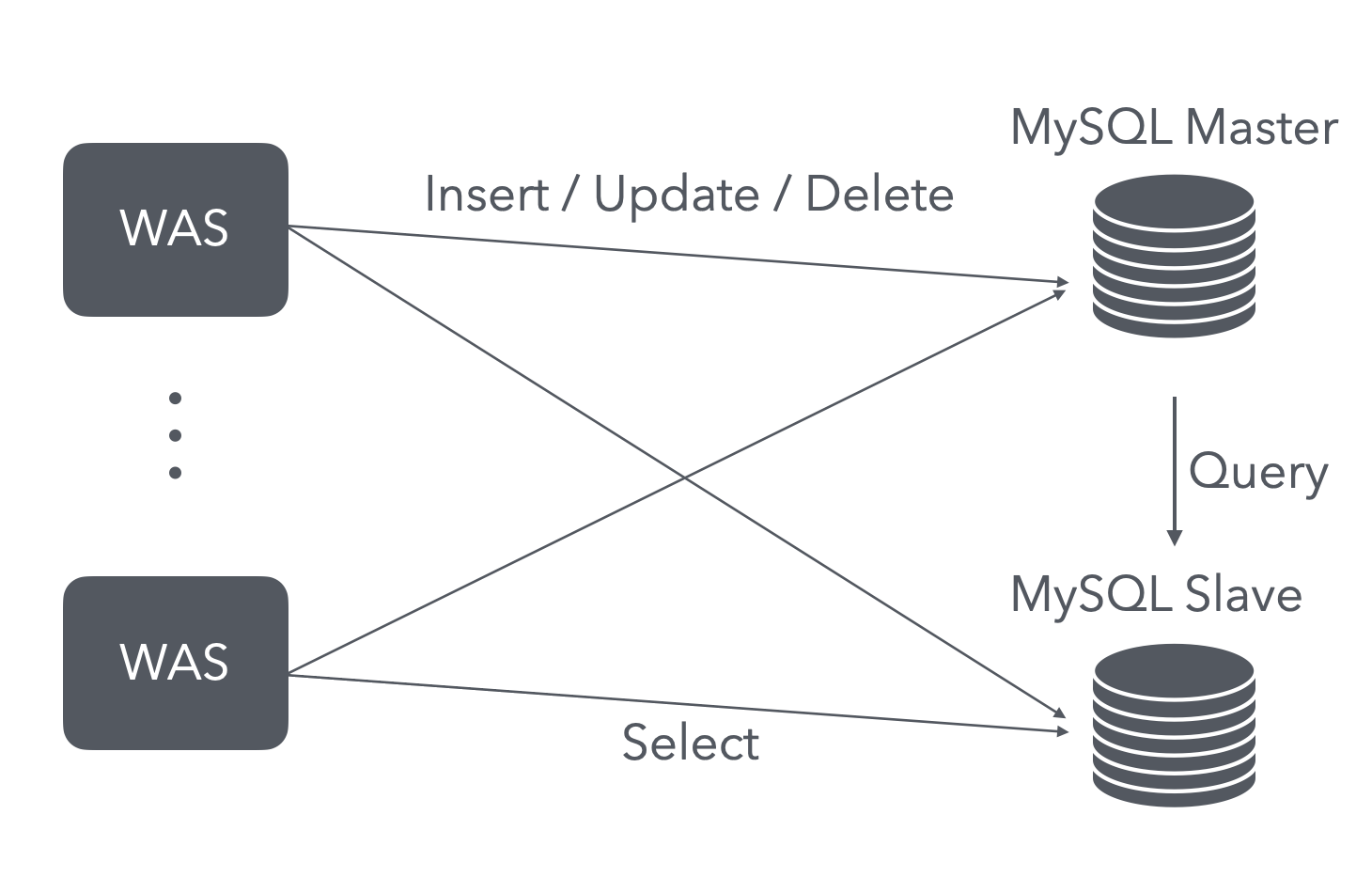
위 구조를 설명하면 WAS에서 발생하는 Write 성격의 멱등하지 않은 연산들은 Master 노드로 분산시키고 Read 성격의 멱등한 연산들은 Slave 노드를 분산시켜서 DDL 요청을 분산시킨다. 이러한 환경을 구축하기 위해 스프링에서 @Transactional의 readOnly 옵션을 활용할 예정이다. 해당 어노테이션을 사용할 경우, 메서드에 AOP가 걸리게 되어 트랜잭션 로직이 (autocommit=false부터 rollback or commit까지) 수행되게 된다. readOnly 옵션의 경우 해당 메서드가 읽기 연산만을 수행할 경우 true 값으로 설정해 DB에게 readOnly임을 알려 성능상의 이점을 가져갈 수 있다.
DataSource
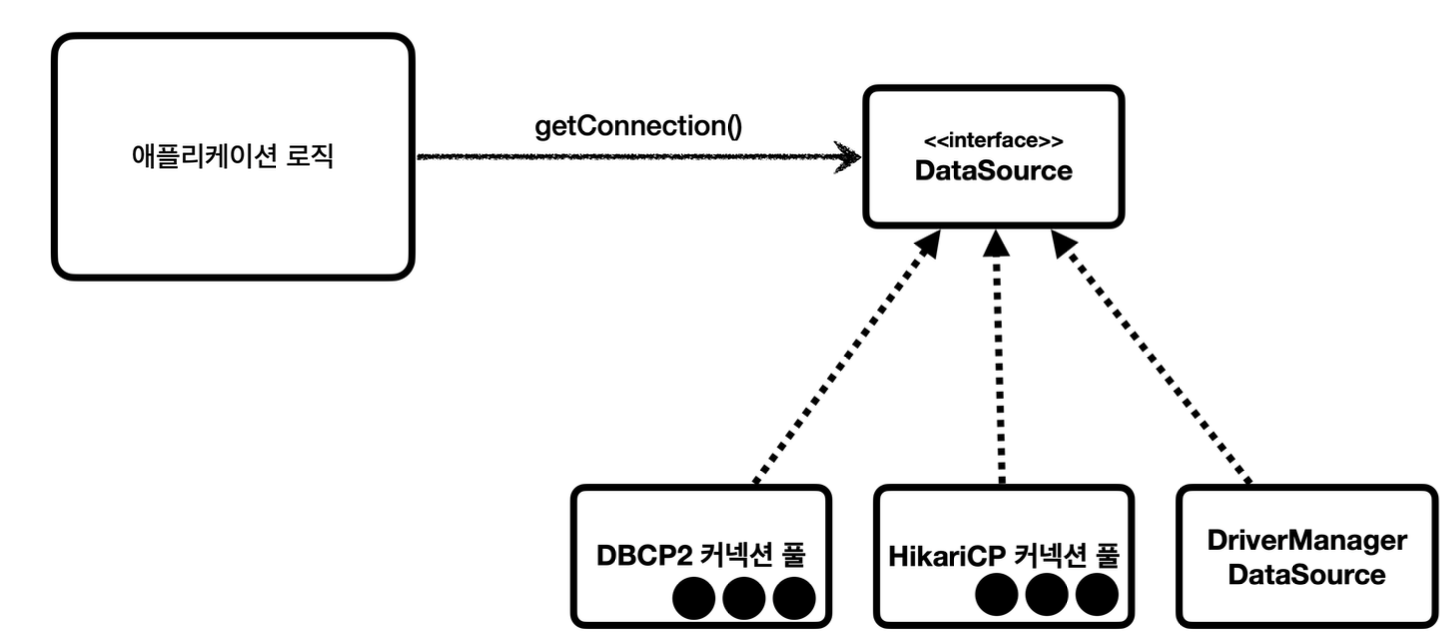
본격적인 구현에 앞서 기본 개념을 짚고 가보자. DataSource는 커넥션을 가져오는 메서드를 제공하는 역할을 수행하는 객체이다.
public interface DataSource
Connection getConnection() throws SQLException;
}
이는 아래 이미지처럼 여러 DB 커넥션 풀 또는 DB 커넥션 생성 객체로부터 커넥션을 가져오는 방법을 추상화 시켜주는 인터페이스이다. 즉, 개발자가 구현체만 갈아끼우면서 커넥션을 가져오는 구현 기술을 변경할 수 있다.
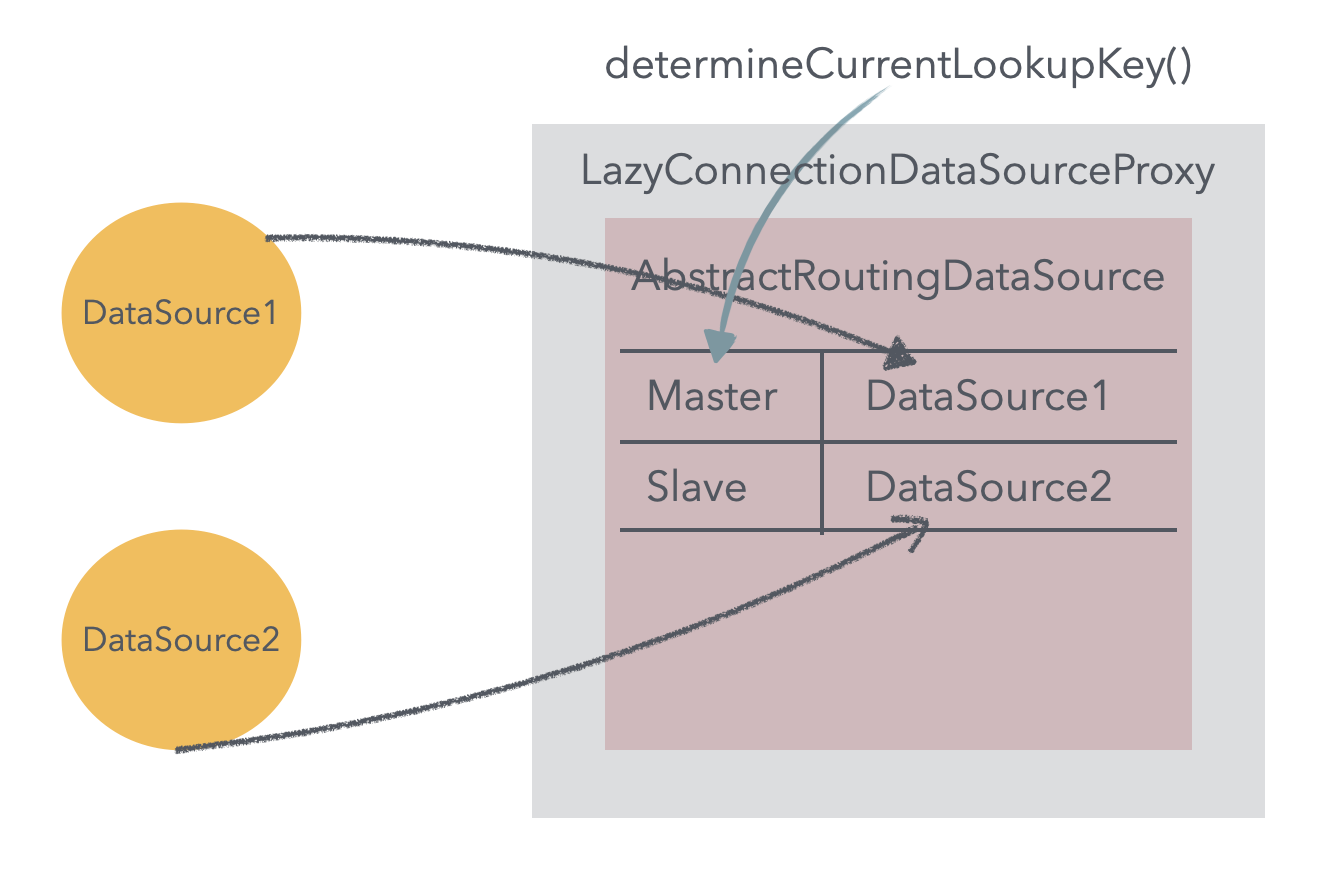
본 포스팅에서는 master-slave 두 개의 DB를 연결하기에 두개의 DataSource를 먼저 만들어줘야한다. 이후 생성된 두 데이터 소스를 AbstractRoutingDataSource을 구현한 데이터 소스의 Map에 추가해주면 된다. AbstractRoutingDataSource는 스프링에서 데이터 소스 라우팅을 위해 제공하는 추상 클래스이다. 해당 클래스의 추상 메서드인 determineCurrentLookupKey를 구현하여서 특정 상황에 맞는 key 값을 리턴시켜줄 수 있다. 이렇게 리턴된 key를 통해 데이터소스 map에서 특정 데이터 소스를 꺼내 이를 사용하도록 할 수 있다. 즉, 맵의 key-value 값을 통해서 데이터소스를 라우팅 시켜줄 수 있다.이미지로 나타내면 아래와 같다.해당 로직이 사실 라우팅 데이터 소스의 핵심적인 내용이다. 꼭 이해하길 바란다.
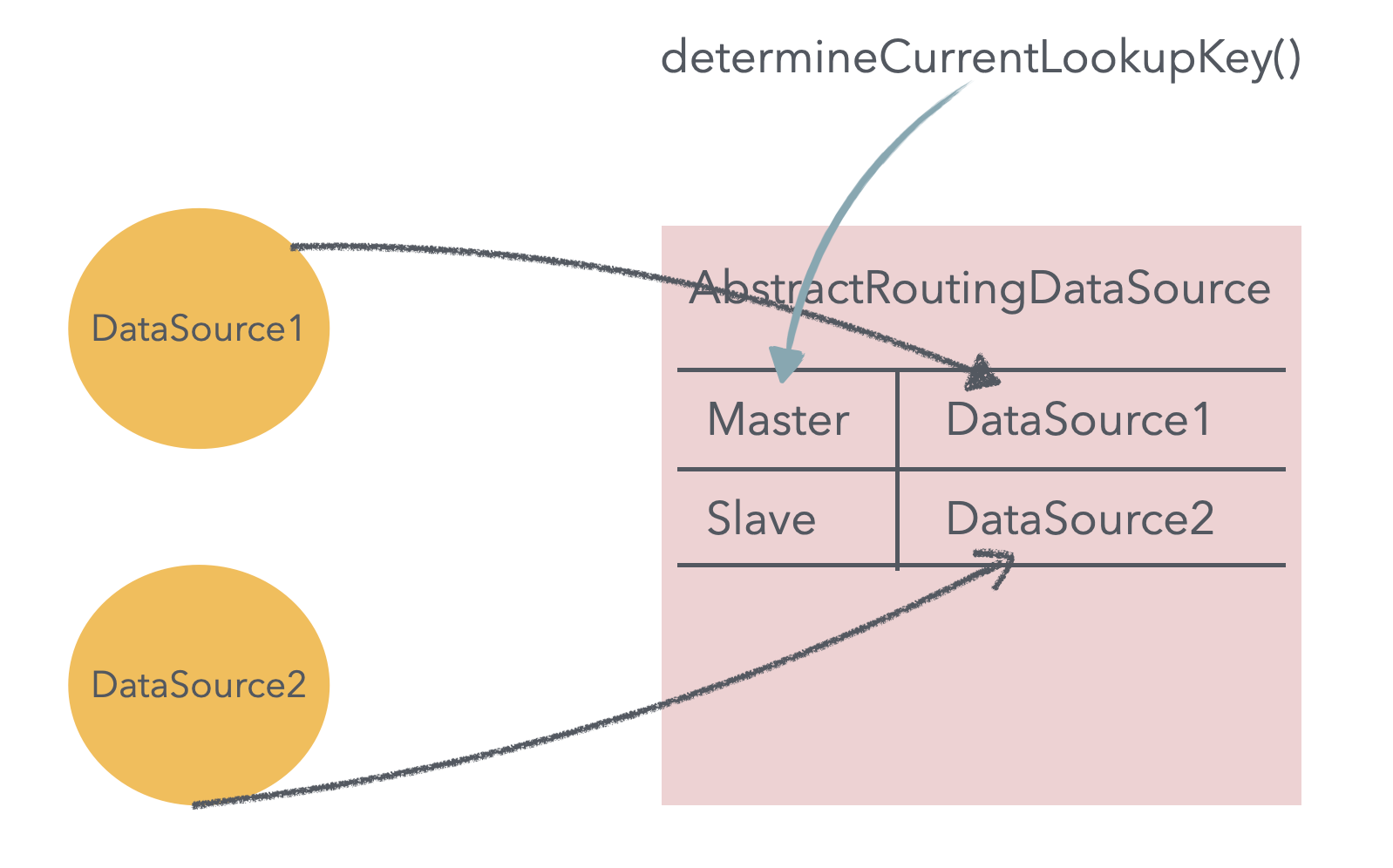
Master 또는 Slave 값을 가지는 키 값은 현재 실행되고 있는 트랜잭션의 매니저를 통해서 값을 가져올 수 있다. 해당 트랜잭션 동기화 매니저가 가진 readOnly 불리언 값이 true이면 slave로 false이면 master로 라우팅하여 구현할 수 있다.
구현
우선 properties.yaml 파일에 데이터소스의 정보를 먼저 기입한다.
spring:
jpa:
database: mysql
hibernate:
ddl-auto: update
generate-ddl: true
show-sql: true
datasource:
primary:
jdbc-url: jdbc:mysql://localhost:3306/test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
secondary:
jdbc-url: jdbc:mysql://localhost:3307/test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
primary와 secondary로 구성을 하였고 각각 mysql을 사용해서 master-slave 형상을 구성하였다.
이후 Config에 위 데이터 소스들의 정보를 빈으로 등록시켜준다. 스프링부트에서 기본 커넥션 풀 구현체를 Hikari를 사용하기에 이를 그대로 따라서 사용하였다.
@Configuration
public class DataSourceConfig {
@ConfigurationProperties(prefix = "spring.datasource.primary")
@Bean
public DataSource primaryDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@ConfigurationProperties(prefix = "spring.datasource.secondary")
@Bean
public DataSource secondDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
}
다음으로 RoutingDataSource를 구현해주면 된다. 이는 앞서 말한 AbstractRoutingDataSource 추상 클래스의 하위 클래스이다. 이 중 map의 key를 찾아주는 determineCurrentLookupKey 메서드를 구현하면 된다.
@Slf4j
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
if (TransactionSynchronizationManager.isActualTransactionActive()) {
String res = isTxReadOnly() ? "secondary" : "primary";
log.info("selected datasource = {}", res);
return res;
}
return null;
}
private boolean isTxReadOnly() {
return TransactionSynchronizationManager.isCurrentTransactionReadOnly();
}
}
트랜잭션 동기화 매니저의 스태틱 메서드를 통해서 현재 트랜잭션의 readOnly 여부를 가져올 수 있다. 트랜잭션 동기화 매니저는 트랜잭션이 열렸을 때 해당 트랜잭션에서 사용되는 DB 커넥션을 가지고 있어 커넥션의 동기화를 유지시켜 주는 역할을 수행한다. 이렇게 가져온 readOnly 값을 통해 데이터 소스 맵에 사용될 키를 결정한다.
다음으로는 위와 같이 설정한 Routing 데이터소스를 빈으로 등록할 차례이다. 앞서 빈으로 등록된 두개의 데이터소스 빈을 사용해서 라우팅 데이터 소스를 빈으로 등록해줘야한다. 이 과정에서 @Qulifier가 사용된다. 해당 어노테이션은 동일한 타입의 빈이 여러개 있을 때 이를 구분해주기 위해서 사용한다.
@Configuration
public class DataSourceConfig {
// ...
@DependsOn({"primaryDataSource", "secondDataSource"})
@Bean
public DataSource routingDataSource(
@Qualifier("primaryDataSource") DataSource primary,
@Qualifier("secondDataSource") DataSource secondary
) {
DynamicRoutingDataSource routingDataSource = new DynamicRoutingDataSource();
Map<Object, Object> map = new HashMap<>();
map.put("primary", primary);
map.put("secondary", secondary);
routingDataSource.setTargetDataSources(map);
routingDataSource.setDefaultTargetDataSource(primary);
return routingDataSource;
}
@DependsOn({"routingDataSource"})
@Primary
@Bean
public DataSource dataSource(@Qualifier("routingDataSource") DataSource dataSource) {
return new LazyConnectionDataSourceProxy(dataSource);
}
}
이후 최종적으로 데이터 소스 빈을 LazyConnectionDataSourceProxy를 통해 등록시킨다. 이는 이름에서도 알 수 있듯이 생성한 데이터 소스 빈에 프록시 객체를 적용 시키는 것이다. 그 목적은 DB 커넥션 연결의 획득을 실제 요청이 일어나는 시점에 가져오기 위함이다. 이를 적용시키지 않은 기본 설정은 트랜잭션이 시작되는 시점에 데이터소스 객체가 결정되고 커넥션을 가져온다. 브레이크 포인트를 걸어 디버깅을 해보면 프록시를 적용시키지 않을 경우 커넥션을 가져온 다음에 트랜잭션 동기화 매니저에 readOnly 값을 동기화 시켜준다. 즉, 우리가 설정한 데이터 소스 분기 처리가 제대로 동작하지 않게 된다. 이를 방지하기 위해 프록시 객체를 사용해 실제 커넥션을 가져오는 시점을 뒤로 미루는 것이다. 프록시가 적용된 최종적인 형상은 아래와 같이 구현된다.
추가로 소스코드의 경우 일부분만을 추가해두었다. 구글링을 할 경우 코드 원문과 깃헙 주소를 알려주는 포스팅들이 굉장히 많다. 본 포스팅은 단순히 코드를 제공하기보다는RoutingDataSource를 통한 데이터 소스 분산의 동작 원리를 이해하는데 도움이 되었음한다.