1.1 SQL 파싱과 최적화
구조적, 집합적, 선언적 질의 언어
SQL은 단어 그대로 구조적 질의 언어이다. 해당 언어는 아래와 같은 순서로 실행된다. 옵티마이저가 프로그래밍을 대신해서 최적의 계획을 통해 프로시저를 작성한다.
- 사용자 -> SQL -> 옵티마이저 -> 실행계획 -> 프로시저
DBMS 내부에서 프로시저를 작성하고 컴파일 해서 실행 가능하도록 하는것을 SQL 최적화라고 한다.
SQL 최적화
세분화 시키면 아래와 같다.
- SQL 파싱 : 문법적 오류, 의미적 오류(없는 테이블에 접근 등) 체크 후 파싱 트리 생성
- SQL 최적화 : 옵티마이저가 이 단계를 수행한다. 다양한 실행 경로를 생성해서 비교한 후 가장 효율적인 경로를 선택한다.
- 로우 소스 생성 : 옵티마이저가 선택한 경로를 실제 실행 가능한 코드 또는 프로시저 형태로 포맷팅한다.
SQL 옵티마이저
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 핵심 엔진이다. 아래와 같은 최적화 단계를 거친다.
- 전달받은 쿼리의 후보가 될 만한 실행 계획들을 찾는다.(Decision Tree 형태)
- 위 실행 계획들의 예상 비용을 산정한다. 데이터 딕셔너리가 사용된다.
- 최저 비용을 나타내는 실행계획을 선택한다.
실행 계획과 비용
실행 계획 미리보기 기능을 통해 자신이 작성한 SQL이 테이블을 스캔하는지 인덱스를 스캔하는지, 어떤 인덱스가 사용되는지 등을 알 수 있다.
해당 경로의 비용을 근거로 테이블 또는 인덱스를 결정한다. 판단의 근거가 되는 비용은 어지까지나 에상치이다. 실측이 아니므로 차이가 발생한다.
옵티마이저 힌트
옵티마이저 또한 항상 최적의 경로를 선택하지 않는다. 주어진 SQL이 복잡할 수록 더욱 최적의 경로를 선택하기는 어려워진다.(네비랑 똑같다)
개발자는 옵티마이저 힌트를 통해 데이터 엑세스 경로를 변경시킬 수 있다.
주로 아래와 같이 특정 인덱스를 사용하도록 힌트를 설정할 수 있다.
select /*+ INDEX(A 주문일자)*/
A.주문번호, A.주문금액, B.고객명, B.연락처, B.주소
from 주문 A, 고객 B
where ...
위 쿼리는 주문 테이블을 접근할 때 주문일자 컬럼이 선두인 인덱스를 사용하도록 힌트로 지정하였다. 반면에 옵티마이저가 다른 방식을 선택하지 못하게 모든 접근에 힌트를 지정할 수도 있다.
1.2 SQL 공유 및 재사용
소프트 파싱 vs 하드 파싱
옵티마이저가 최적화를 통해 생성한 내부 프로시저를 재사용하도록 캐싱해두는 공간이 아래 이미지의 Library Cache 이다. SGA는 주로 오라클 DBMS에서 사용되는 개념이며 클라이언트의 요청을 처리하는 서버 프로세스와 이를 보조해주는 BG 프로세스에서 해당 영역에 접근한다. 참고로 RDBMS를 구동할 경우 여러 프로세스에 의해 구동된다.
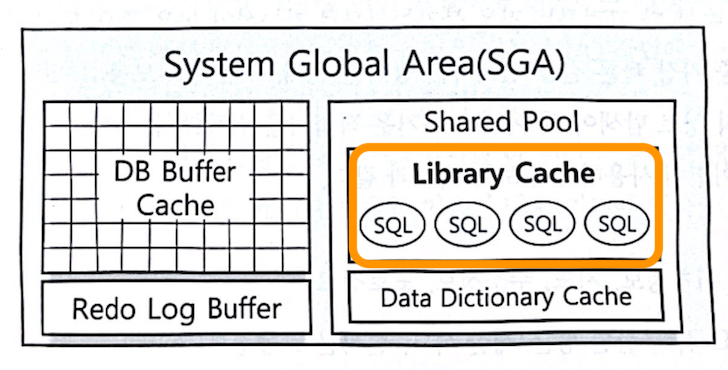
사용자의 SQL이 파싱되면 해당 SQL이 라이브러리 캐시에 존재하는지 확인한다. 이후 cache-hit인 경우 해당 로우소스를 사용하고 cache-miss인 경우는 로우 소스를 생성하기 위한 과정을 옵티마이저가 수행한다. <SQL문, 로우소스> 형태의 key-value로 캐시가 구성된다고 이해하였다.
캐시가 적중할 경우 이를 소프트 파싱이라 하고 미스가 발생할 경우는 하드 파싱이라고 한다. 하드 파싱의 경우 SQL 최적화 과정을 거치는데 이러한 작업이 많은 오버헤드를 수반하여 “하드” 라는 의미가 부여되었다.
옵티마이저가 하나의 쿼리를 최적화 하기 위해 아래와 같은 다양한 정보들을 사용한다.
- 테이블, 컬럼, 인덱스 구조에 관한 기본 정보
- 오브젝트 통계
- 시스템 통계
- 옵티마이저 관련 파라미터
이러한 정보들을 활용해 다량의 CPU 연산을 처리해줘야한다. IO 작업에 비하면 미비할 지는 몰라도 연산 자체의 양이 많기에 캐싱 전략을 사용한다.
바인드 변수의 중요성
앞서 살펴본 라이브러리 캐시는 <SQL문, 로우소스> 형태로 저장된다.
만약 여기서 아래와 같은 jdbc 코드가 수많은 요청을 동시에 받으면 어떻게 될까?
public void login(String id) throws Exception {
String SqlStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = " + id + "'";
//쿼리 실행 로직...
}
아마 배운대로라면 아래 SQL 전부에 대한 각각의 하드 파싱이 적용된다. 왜냐하면 캐시의 키값이 다르기 때문이다.
SELECT * FROM CUSTOMER WHERE LOGIN_ID = 'brido'”SELECT * FROM CUSTOMER WHERE LOGIN_ID = 'daeback'”
즉,I/O 연산이 아닌 CPU 연산에 의한 부하로 인해 장비의 리소스가 급격히 사용됨을 예상해볼 수 있다.
이를 해결하기 위해 jdbc에서 아래와 같이 ? 인자를 사용한다.
public void login(String id) throws Exception {
String SqlStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = ?";
PreparedStatement st = con.prepareStatement(SqlStmt);
st.setString(id);
//...
}
위와 같이 적용할 경우 "SELECT * FROM CUSTOMER WHERE LOGIN_ID = ?"에 해당하는 로우 소스를 최초 한번만 하드 파싱하고 이후 모든 요청들이 재사용할 수 있다.
1.3 데이터 저장 구조 및 I/O 메커니즘
IO 작업의 경우 SQL 작업이 느린 주된 원인이다. 그럴 수 밖에 없는게 IO 요청을 보내게 될 경우 해당 프로세스는 Blocking되어 대기 상태에 들어간다. I/O 호출 속도는 아래와 같다.
- Single Block I/O : 평균 10ms -> 초당 100개 블록 정도(1블록 당 10ms)
- SSD 활용 I/O : 1ms에서 2ms
데이터 베이스 저장 구조
데이터를 저장하려면 테이블 스페이스가 필요하다. 테이블 스페이스는 세그먼트를 담는 컨테이너이다. 세그먼트는 테이블,인덱스처럼 데이터의 저장공간이 필요한 오브젝트이다.이러한 세그먼트는 여러개의 익스텐트로 구성된다. 익스텐트는 공간을 확장하는 단위이다.테이블이나 인덱스에 데이터를 입력하다가 공간이 부족할 경우 테이블 스페이스로부터 추가로 할당받는다. 동시에 익스텐트는 연속된 블록들의 집합이다. 블록은 사용자가 입력한 레코드가 실제로 저장되는 공간이다. 또한 한 블록은 한 테이블이 독점한다.즉, 하나의 블록에 저장된 레코드들은 모두 같은 테이블의 레코드들이다.
그러면 실제 데이터파일에 익스텐트들이 저장이 될 텐데, 연속된 익스텐트들이 존재할 경우 모두 같은 하나의 데이터 파일에 저장될까? 아니다. 이들은 서로 다른 데이터 파일에 위치할 가능성이 높다. 왜냐하면 하나의 파일에 여러 익스텐트들이 구성될 경우 파일을 읽으려는 경합이 증가할 수 있기 때문이다. 앞서 나온 용어들을 간략히 정리하자.
- 블록 : 데이터를 읽고 쓰는 단위
- 익스텐트 : 공간을 확장하는 단위, 연속된 블록의 집합
- 세그먼트 : 데이터 저장공간이 필요한 오브젝트(테이블, 인덱스, 파티션 ,LOB)
- 테이블 스페이스 : 세그먼트를 담는 컨테이너
- 데이터 파일 : 디스크 상의 물리적인 OS 파일
블록 단위 I/O
앞서 언급된 것처럼 데이터를 읽고 쓰는 단위가 블록이다. 그러므로 특정 레코드 하나만 읽고 싶다고 해도 해당 레코드가 포함된 블록을 통째로 읽어야한다.
테이블뿐만 아니라 인덱스 또한 특정 레코드를 찾아내 읽을 때 해당 레코드가 담긴 블록 단위로 읽는다.
시퀀셜 액세스 vs 랜덤 액세스
시퀀셜 엑세스는 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는다.대표적인 예로 인덱스의 리프 노드들의 주소값을 따라 블록을 읽는 경우를 들 수 있다. 또한 테이블의 경우 각 익스텐트의 첫 번째 블록 주소값을 활용해 시퀀셜하게 블록에 접근 가능하다.
반면에 랜덤 엑세스는 하나의 블록에 순서를 따르지 않고 접근하는 방식이다.
논리적 I/O vs 물리적 I/O
앞서 살펴본 Library Cache 이미지에서 DB Buffer Cache 영역이 있었다. 라이브러리 캐시가 SQL과 실행계획,프로시저 캐싱하는 영역이라고 한다면 DB 버퍼 캐시는 데이터 캐시라고 할 수 있다. 이는 디스크 블록으로부터 읽은 데이터를 캐싱해 두어 같은 블록에 대한 반복적인 I/O 작업의 횟수를 줄여준다.
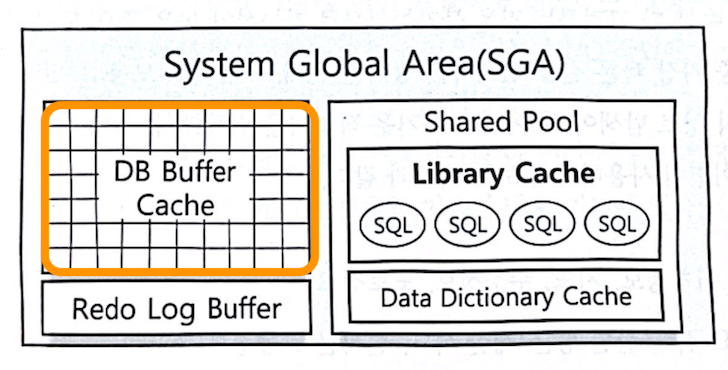
논리적 I/O라고 함은 SQL문을 처리하는 과정에서 메모리 버퍼 캐시에서 발생하는 총 블록 I/O를 의미한다. 반면 물리적 I/O라고 함은 디스크에서 발생한 총 블록 I/O를 의미한다. 캐시 메모리는 보통 물리 메모리에 존재하기에 디스크 I/O에 비해 약 10,000배쯤 빠르다.
SQL을 수행하려면 데이터가 담긴 블록을 읽어야 한다. 특정 SQL이 참조하는 테이블에 변경이 없고 같은 변수를 입력하면, 몇번을 수행해도 매번 읽어야 하는 블록 수는 같다. SQL을 수행하면서 읽은 총 블록 I/O의 수가 논리적 I/O다. 그러면 앞서 절에서 왜 논리적 I/O가 메모리 버퍼 캐시에서 발생하는 블럭 I/O의 수라고 표현했을까? Direct Path Read 방식으로 읽는 경우를 제외하면 모든 블럭은 DB 버퍼 캐시를 경유해서 읽는다. 따라서 논리적 I/O의 횟수는 DB 버퍼 캐시에서 블록을 읽은 횟수와 동일하다.
반면 만약 캐싱에 실패해 블록에서 찾지 못하면 디스크에서 해당 블록을 읽어오고 이를 물리적 I/O라 한다. 앞선 조건처럼 테이블의 데이터 변경이 없고 같은 변수를 입력하더라도 물리적 I/O는 동일한 SQL이라하더라도 달라질 수 있다. 첫번째 요청에 물리적 I/O보다 그 다음 요청은 물리적 I/O가 감소할 수 밖에 없다.
흔히 SQL을 튜닝한다는것은 논리적 I/O를 감소시켜 가져오는 블록 자체를 감소시키는것을 의미한다. 물리적 I/O의 경우 매 요청마다 고정된 값이 아니기에 튜닝의 대상이 되기 어렵다. 그래서 논리적 I/O 자체를 감소시키면 자연스레 통제 불가능한 변인인 물리적 I/O 또한 감소하게 된다.
Single Block vs MultiBlock IO
캐시에서 찾지못한 블록의 경우 디스크로부터 DB 버퍼캐시로 적재하고 나서 읽는다.이때 발생하는 I/O 요청이 한 번에 한 블록씩 요청하기도 하고 여러 블록씩 요청하기도 한다. 한 요청의 한 블럭을 Single Block이라고 한 요청에 여러 블록을 가져올 때는 MultiBlcok이라고 한다.
인덱스를 이용할 경우 기본적으로 인덱스와 테이블 블록 모두 Single Block 방식을 사용한다. 인덱스는 주로 소량의 데이터를 읽는 경우가 많으므로 이 방식이 효율적이다.반대로 많은 데이터 블록을 읽을 때는 MultiBlock 방식이 효율적이다. 그래서 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 이 방식을 사용한다. 한번에 많은 블럭이 필요할 때 한 블럭씩 가져오게 되면 결국 I/O 요청에 의한 블록킹이 발생하여 요청 시간이 길어지게 된다.이러한 점 때문에 특정 블록과 그 근처 블록들을 한꺼번에 읽어들이는 MultiBlock이 효율적인 경우도 존재한다.
메모리 퍼버 캐시 탐색
버퍼 캐시는 SGA의 구성 요소임으로 캐싱된 버퍼 블록들은 공유 자원이다. 즉, 여러 프로세스로부터 동시에 특정 블록에 접근하는 경우가 발생한다. 따라서 자원을 공유하는것처럼 보여도 실제로 내부에서는 한 프로세스씩 순차적으로 접근하도록 구현하는 직렬화를 제공한다.(직렬화를 ‘줄 세우기’라고 표현했고 이해하기 쉬운것 같다) 프로세스간의 순서를 보장하기 위해 캐시버퍼 체인 래치를 제공한다.