아마 하나의 프로그래밍 언어를 지정해서 공부를 하시다보면 컴파일이라는 단어를 수없이 듣게 될 것입니다.이번 포스팅에서는 컴파일 과정과 python의 컴파일 방식을 간략하게 알아보겠습니다.
컴퓨터에게 명령을 전달하는 법
기본적으로 저희는 아래와 같은 High-Level언어를 통해서 컴퓨터에게 명령을 전달합니다.그렇다면 인간의 눈에 읽히는 아래와 같은 C언어 코드가 기계에게 그대로 읽힐 수 있을까요? 그렇지 않습니다.지금부터 아래의 간단한 코드가 기계어로 변환 되는 과정을 알아보겠습니다.
#include <stdio.h>
typedef struct Point{
int x;
int y;
}point;
int main() {
int x = 10;
int *y = &x;
printf("x의 주소값 : %p\n", &x);
printf("포인터 y의 주소값 = %p\n", y);
printf("포인터 y가 가지는 값 = %d\n", *y);
point p1 = {.x = 12,.y = 34};
printf("p1의 주소 = %p\n", &p1);
printf("p1의 X값 = %d, y값 = %d\n", p1.x,p1.y);
point *P = &p1;
printf("포인터의 P의 주소 = %p\n", P);
printf("포인터 P의 X값 = %d, y값 = %d\n", P->x,P->y);
return 0;
}
아래의 모든 실습 과정은 gcc 컴파일러의 도움을 받아 unix계열의 환경에서 진행합니다.혹시 맥 또는 리눅스에 gcc가 없다면 아래의 명령어로 설치합시다.
sudo apt install build-essential
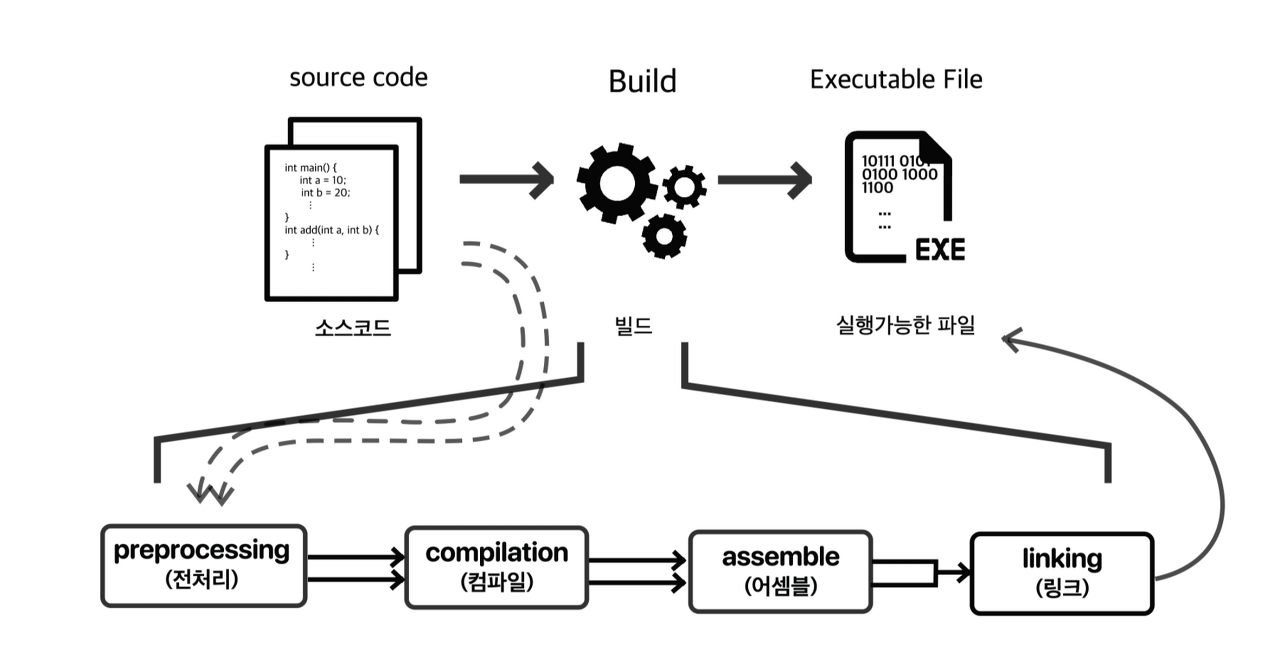
- 전처리 단계
gcc -E main.c
해당 과정을 간략하게 말하자면 #으로 시작하는 헤더파일 또는 매크로를 처리해주는 과정입니다.위의 코드에서는 #include <stdio.h>와 같이 stdio.h 파일이 해당 프로그램을 실행시킬때 필요하다고 알려준다고 생각하셔도 됩니다.또한 python에 대한 경험이 있으시면 import와 비슷하다고 이해하셔도 좋을 것 같습니다.위의 명령어를 수행할 경우 아래와 같은 결과가 보이실껍니다.저희가 추가하려는 헤더파일을 SDK에서 찾아 명령어로 넣어주는것을 결과물 중간 쯤에서 확인 할 수 있습니다.
2. 컴파일 단계
gcc -S hello.c
위의 명령어를 수행할 경우 아래와 같이 main.s 라는 파일을 컴파일러가 생성해줍니다.이와 같은 컴파일 과정을 거치면 인간이 최소한으로 이해할 수 있는 마지막 단계의 코드인 어셈블리어로 구성된 코드가 생성됩니다.

궁금하니 해당 파일을 다음과 같은 명령어로 한번 읽어보겠습니다.
cat main.s
알듯 말듯한 영어와 기호들이 절묘하게 섞여 있는 것을 보실 수 있습니다.지금 단계에서 저희가 어셈블리어를 해석해야할 일은 없기 때문에 컴파일을 통해 어셈블리어로 구성된 파일이 발생하는구나라는 것 정도만 알아도 좋습니다.
3. 어셈블 단계
이전단계의 어셈블리어로 구성된 .s 파일을 컴퓨터가 이해할 수 있는 기계어로 구성된 .o 파일로 변환합니다.이 파일은 저희가 실행할 프로그램의 명령어를 포함하는 바이너리 파일이라고 생각하시면 됩니다.참고로 바이너리 파일은 저희가 읽을 수 있는 텍스트 파일을 제외한 모든 파일입니다.아래의 명령어를 통해 바이너리 파일을 한번 만들어 봅시다.
gcc -c main.c
저희가 읽을 수 없는 파일을 한번 읽어보겠습니다.보시는 바와 같이 정말 쓰레기 문자들이 잔뜩 들어가 있습니다.

4. 링크 단계
직관적으로 보셔도 무언가를 연결해 줄 것 같은 느낌이 드는 단계입니다.이론적으로는 실행할 목적파일이 필요로 하는 다른 목적파일을 연결해주는 역할을 수행합니다.서로다른 목적 파일간 연결을 마치면 그 결과물을 만들어줍니다.여기서 결과물이란 바로 실행파일입니다.이 역시 아래의 명령어로 직접한번 만들어 봅시다.
gcc main.c -o main
아래 이미지의 빨간색으로 보이는 main이라는 파일이 보이시나요?글을 시작할 때 보여주었던 C 언어로 구성된 파일을 드디어 실행시킬 수 있는 파일로 만들어낸것입니다.

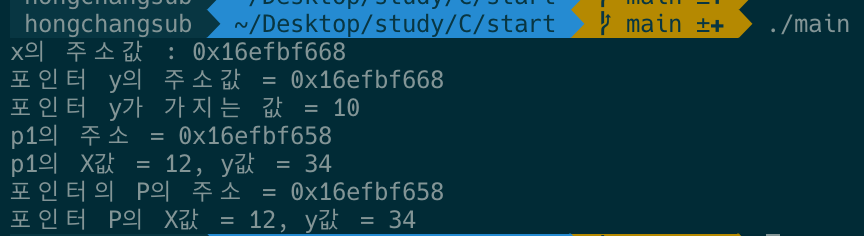
심지어 아래와 같이 ./main을 통해 실행을 시키면 코드가 깔끔하게 실행되는 것을 확인가능합니다.
이렇게 실습 위주로 저희가 만든 C언어가 어떻게 실행되는지 단계별로 알아 보았습니다.
인터프리터 vs 컴파일 언어
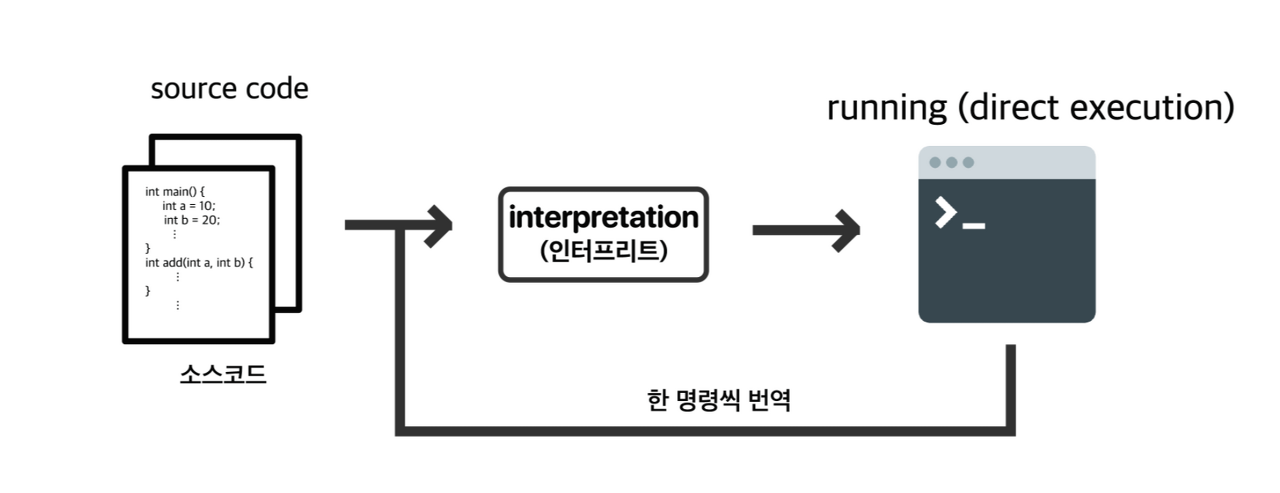
이제 컴파일이 어떤것인지 배웠으니 항상 컴파일 언어와 함께 항상 비교가 되는 인터프리터 언어에 대해 알아봅시다.우선 Interpreter라는 단어를 알고 계시나요?간단하게 직역하면 통역사입니다.단어의 본래 뜻을 잘 살려서 실제 Interpret 언어들은 실시간으로 한줄 한줄 저희가 작성한 코드들을 해석해서 컴퓨터에게 전달합니다.반면에 컴파일 언어의 경우 위에서 저희가 배운 바와 같이 작성한 코드를 한번에 모아서 어셈블리어로 만들고 이를 통째로 기계어로 번역해버리는 방식입니다.조금 쉽게 예를 들어 설명하겠습니다.저희가 뜬금없이 길가다 터키인을 만났다고 가정합시다.여기서 이를 해결하기 위한 두가지 상황으로 나누어집니다.
- 번역기 어플을 돌리거나
- 터키어를 잘하는 친구에게 전화를 하는 것입니다.
번역기 어플의 경우 터키인 말을 한줄 한줄 바로 읽어 저희에게 통역을 할 것이고,터키어를 잘하는 친구의 경우 터키인의 말을 모아서 듣고나서 저희에게 한번에 통역해 줄 것입니다.번역기 어플이 인터프리터이고, 터키어를 잘하는 친구가 컴파일 언어라고 생각하시면 됩니다.
그래서 인터프리터의 경우 한줄 한줄 코드가 매번 CPU에게 전달되어야 하기에 컴파일 언어에 비해 속도가 느립니다.(python이 C에 비해 느린 한 가지 이유를 여기서 찾을 수 있습니다)반면 컴파일 언어의 경우 해당 컴퓨터의 컴파일러에 의해 어셈블리어의 결과가 조금씩 다르기에 플랫폼에 의존적라고 볼 수 있습니다.(쉽게 말하면 윈도우와 맥에서 사용하는 컴파일러가 달라, 동일한 코드에서 나오는 .s파일이 완전히 동일하지는 않습니다)
간단한 개념을 잡았으니 저희가 만든 파이썬 파일이 어떻게 컴퓨터에게 명령으로 들어가는지 알아봅시다.
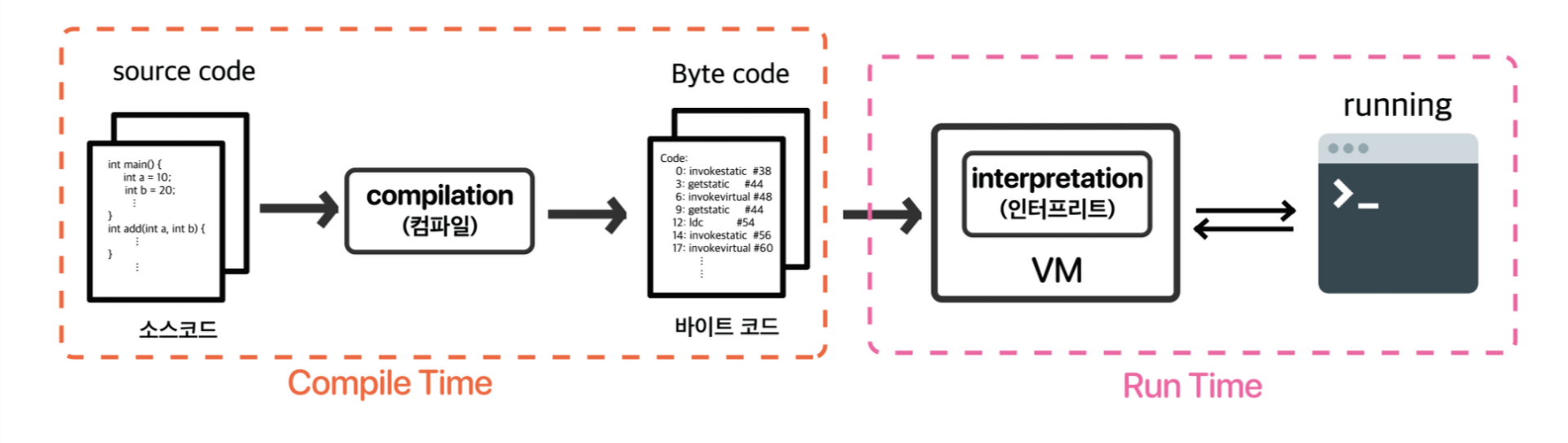
.py가 실행되는 과정
파이썬은 대부분 인터프리터 언어라고 합니다.하지만 실상은 애매합니다.파이썬은 기본 인터프리터인 CPython을 통해 저희가 작성한 코드를 바이트 코드로 컴파일시키는 과정이 존재합니다.이후 컴파일 된 바이트 코드를 PVM(Python Virtual Machine)으로 한줄 한줄씩 인터프리터 방식으로 CPU에 명령을 전달합니다.
우선 PVM부터 설명을 하겠습니다.간단하게 비유를 하자면 생성된 파이썬 바이트 코드를 한줄 한줄 읽을 수 있는 가상 컴퓨터라고 이해하셔도 좋습니다.이러한 VM 안에는 바이트 코드를 해석할 수 있는 인터프리터가 있어 이들이 바이트 코드를 해석해서 각 OS에 맞게 명령어를 해석하고 작동시킵니다.
바이트 코드의 경우 인터프리터의 속도 문제, 컴파일의 의존적인 문제를 보완하기 위해 생겼습니다.그래서 앞서 설명한 가상머신(PVM)이 이해할 수 있는 중간 언어(대략 어셈블리어와 비슷한 느낌)라고 보시면 됩니다.즉, 어셈블리어는 어셈블러라는 하드웨어에 의해 해석이 되지만 바이트코드는 가상머신(VM)이라는 소프트웨어에 의해 처리되는 것이 가장 큰 차이점입니다.
결론적으로 VM을 사용하여 플랫폼에 독립적인, 즉 하드웨어의 영향을 받지않으며 기존의 인터프리터 언어에 비해 바이트코드를 통해 한 발 더 기계어에 가까운 언어를 해석하기에 속도 문제도 보완할 수 있게 되었습니다.
저희가 백준에서 TLE가 발생할 경우 찾는 pypy의 경우 앞서 말한 기본 인터프리터 CPython을 대체하는 인터프리터라고 이해하시면 됩니다.즉,인터프리터를 CPython이 아닌 python 자체로 구현된 pypy라는 인터프리터를 채택한것입니다.이러한 pypy가 파이썬의 속도를 개선하는 중요한 방법은 바로 캐싱입니다.캐싱을 통해 자주 쓰이는 코드를 메모리에 저장하고 있습니다.(아마 pypy에서 메모리 초과가 python3보다 잘 발생한 이유가 캐싱에 있다고 생각합니다.)