이번 글은 Future와 CompletableFuture의 동작을 간단히 소개하고, 왜 Future 타입의 경우 100% non-blocking이라고 할 수 없는지 그리고 이를 해결하기 위해 어떤 점이 개선되어야 하는지 알아봅니다.
Future 인터페이스의 문제점
대부분의 개발자가 알고 있듯이, Future는 아래 이미지와 같은 시퀀스를 통해 비동기 작업의 처리 결과를 받아옵니다. 즉, 요청을 보내는 스레드가 Blocking이 될 수도 있다는 것이죠.(특히 IO 작업일 경우는 거의 100%라고 볼 수 있겠죠)
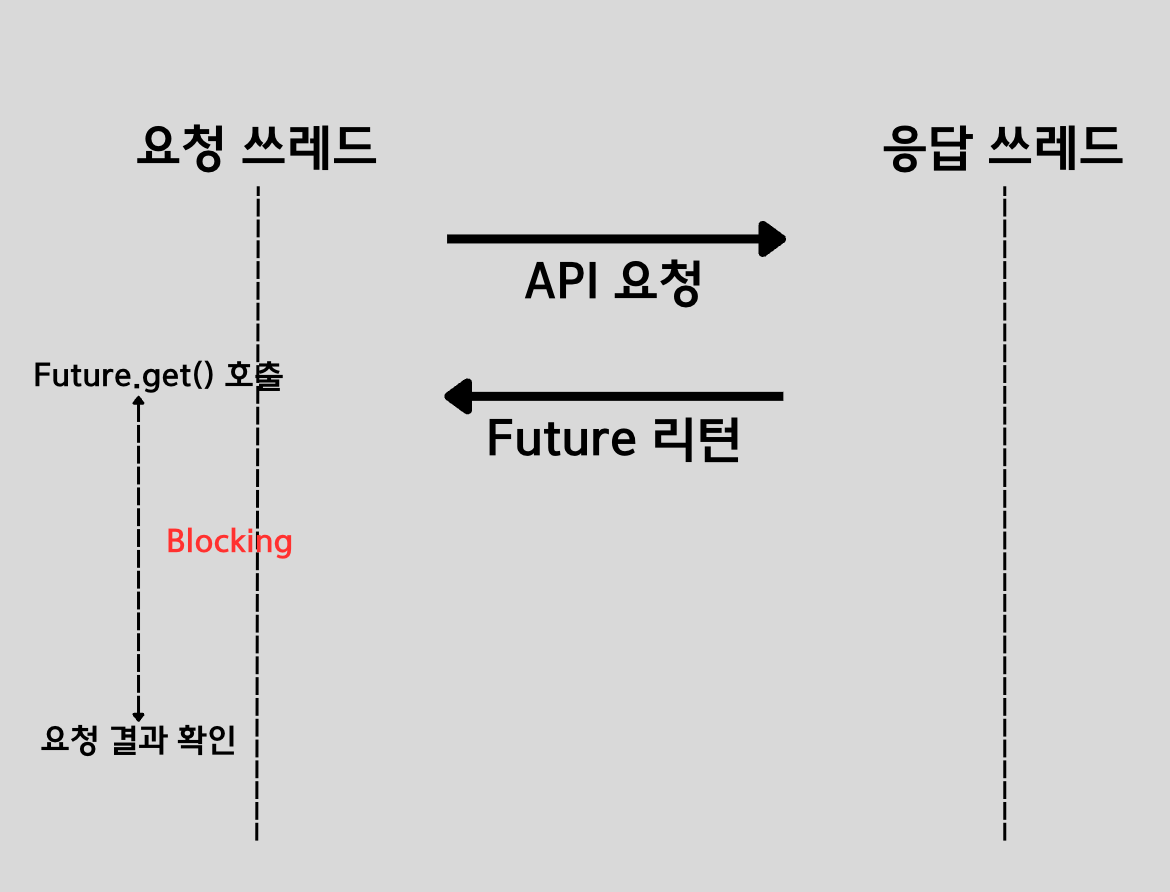
즉, 위와 같은 Blocking이 발생하면 요청하는 스레드가 수ms에서 길게는 수십ms 동안 대기를 하게 됩니다. 이러한 블로킹 시간이 높은 응답성을 요구하는 WAS에서 중복적으로 소요될 경우에 이는 결국 사용자의 경험을 감소시키는 문제를 초래할 수 있습니다. 예를 들어 spring mvc를 스프링 부트를 통해 사용하는 WAS의 경우 내부적으로 톰캣 스레드풀이 HTTP 요청에 대한 응답처리를 수행합니다. 즉,톰캣 스레드의 주된 목적은 자신이 받은 요청에 대한 응답을 빠르게 처리하는 것입니다. 이러한 목적을 갖는 스레드에게 위와 같은 블로킹 시간은 성능 측면에서 피해야할 부분이 됩니다.
CompletableFuture로 눈속임하기
비지니스 로직 내에서 앞선 Future를 리턴하는 API를 사용해야하는 경우 어떻게 이를 조금이나마 효율적으로 사용해볼 수 있을까요? Java8 부터 제공되는 CompletableFuture를 사용할 경우, 톰캣 스레드가 블로킹 당하는것을 막아 스레드의 응답성을 조금이나마 늘려볼 수 있습니다. 물론 이러한 방식이 근본적인 블로킹 문제를 해결해주지는 않습니다.
아래와 같은 테스트 코드가 있습니다.
@Test
public void before() throws InterruptedException {
ArcusClientPool clientPool = ArcusClient.createArcusClientPool("test", new ConnectionFactoryBuilder(), 2);
CompletableFuture<Boolean> cf = CompletableFuture.supplyAsync(() -> {
Boolean result = null;
try {
result = clientPool.set("testKey", 3, "value").get();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
Thread.currentThread().interrupt();
}
return result;
});
//callback 처리
cf.thenAcceptAsync(result -> {
log.info("result = {} ", result);
}).exceptionallyAsync(t -> {
log.info("t = {}", t.getCause().getMessage());
return null;
});
log.info("main thread done.");
Thread.sleep(300);// prevent interrupt to common pool.
}
Arcus 라는 캐시 서비스를 통해 3초동안 유효한 "testKey" / "value" 라는 데이터를 각각 key-value로 하여 저장하는 api를 호출하고 있습니다. 해당 api의 응답 타입은 Future이고 get() 메서드를 통해 요청에 대한 Boolean 타입의 결과를 받아 올 수 있습니다. 이러한 요청을 보낸 톰캣 스레드는 CompletableFuture.supplyAsync를 통해서 원래는 자신이 블로킹 당해야할 로직을 common-pool에게 맡길 수 있습니다. 이후, 톰캣 스레드는 비지니스 로직을 수행하여 응답을 보내고 자신은 또 다른 요청을 받아들일 수 있습니다.
다만 위 방법의 경우 아래와 같은 한계가 있습니다. 만약 api의 응답 결과가 HTTP 요청의 응답에 필수적인 경우, 결국 해당 결과를 받아오기 위한 블로킹은 피할 수 없습니다. 또 다른 관점의 문제는 supplyAsync를 통해 common-pool 또는 사용자 정의 스레드풀에게 블로킹 작업을 맡길 수 있는데 사용자 정의 스레드풀을 사용한다면 풀을 유지해야하는 비용 또한 발생합니다.
결국 Future 타입을 리턴하는 api가 존재한다면 이를 사용하는 입장에서는 api의 결과값이 필요로 하지 않게 로직을 작성하는 방식으로 블로킹을 피할 수는 있습니다. 하지만 근본적인 문제는 해결되지 않았죠.
Future 인터페이스가 가지는 문제점
Future 인터페이스만을 구현한 타입을 리턴하는 api는 어떤 부분이 문제라서 위와 같은 블로킹 시간을 피할 수 없을까요?
첫번째 api 요청이 처리된 후,수행할 콜백을 처리해주는 메서드가 존재하지 않습니다. CompletableFuture의 경우 whenComplete, thenAccept 등 다양한 함수형 인터페이스를 인자로 받는 콜백 메서드들을 제공해주고 있습니다.이러한 메서드를 활용하여 개발자는 좀 더 편하게 요청에 대한 결과에 대한 처리를 수행할 수 있습니다.
두번째로 CompletableFuture 의 경우, 비동기 작업의 완료 시점 후에 개발자가 설정한 콜백 메서드가 수행되도록 하는 내부 구현이 존재합니다. 좀 더 살펴보면 내부에 complete() 라는 메서드가 있고 이는 수행중인 비동기 로직이 완료될 경우 호출하여 작업의 완료 여부를 결정해줍니다. Future의 경우에도 isDone()이라는 추상 메서드를 제공하여 비동기 작업의 완료 여부를 확인할 수는 있지만 Future 자체적으로 완료 여부를 결정해주는 메서드를 제공해주지는 않습니다. 일반적인 패턴으로 CountDownLatch를 사용하여 Future.get() 메서드를 구현하여 완료 여부를 확인할 수 있습니다.
그러면 어떻게 언급된 complete()를 사용한다면 블록킹 당하지 않는 구현이 되는걸까요? 기존의 문제는 캐시 요청을 한 스레드가 future.get()을 통해 항상 결과 값을 기다려야만 했습니다. 만약 캐시 라이브러리 단에서 complete()를 통해 작업의 완료 여부를 결정한다면 캐시 요청을 한 스레드는 콜백으로 수행시킬 로직을 넘겨준 뒤 자신의 로직을 수행하러 가면 됩니다. 즉, 블로킹을 피할 수 있게 되는 것입니다. 이러한 콜백을 설정할 수 있는 메서드 또한 CompletableFuture에서 제공합니다.
물론 Future 또한 인터페이스이기에 개발자가 직접 커스텀하게 CompletableFuture와 비슷한 Future 구현체를 만들 수는 있습니다. 예를 들어 스프링4부터 제공하던 ListenableFuture와 같은 예시가 있습니다. 하지만 이러한 구현체 또한 스프링 6 버전 기준으로 deprecated 되었고, 주석을 읽어보면 CompletableFuture로 대체되어 사용하면 된다라고 명시되어 있습니다.
CompletableFuture를 활용하는 방안
캐시 서비스를 개발하는 벤더의 입장에서 일을 하다보면 필수적으로 고려해야하는 것이 사용자의 편의성입니다. 이러한 편의성을 고려한다면 CompletableFuture 도입은 필수적이죠. 왜냐하면 CompletableFuture 리턴하도록 내부 api를 구현을 변경하면 앞서서 살펴보았던 블로킹 문제가 완전히 해결됩니다. 이는 단순히 블로킹 문제만을 해결하는 것뿐만 아니라, Reactive Stream을 활용하는 Spring webFlux 지원과도 연관이 됩니다. webFlux의 경우 내부적으로 사용되는 api에서 블로킹이 된다면 사용하는 의미가 없어지기 때문입니다.
결론적으로 비지니스 로직에서 외부 api들을 사용하는 경우가 많습니다. 이러한 외부 api들은 네트워크를 타고 IO 작업이 일어나기에 Blocking이 될 수 밖에 없습니다. 사용하는 외부 api가 CompletableFuture를 지원하다면 이러한 블로킹 시간을 줄여 로직의 처리량을 높이는데 활용할 수 있습니다.