Redundant Arrays of Independent Disk의 약자로 복수개의 독립적인 디스크들을 배열 형태로 가지는 구조를 말한다.
이러한 여러개의 디스크로 구성된 드라이브 구조는 redundancy를 통해서 reliability를 확보하는게 목적이다.즉 여러개의 디스크에 데이터를 분산 저장하여서 안정성을 보장하는 구조이다.
RAID 구조는 데이터에 대한 reliability와 데이터 접근시 disk-performance를 향상시키는게 목적이다. reliability의 경우 서술된 것처럼 분산 저장 시켜 놓아서 확보하지만 disk-performance는 어떻게 향상 시킬까? 첫번째, 여러개의 디스크에 분산되어 저장된 하나의 데이터에 대한 조각들을 동시에 접근가능하기 때문이고 이런 병렬적 접근을 통해서 throughput(작업량)을 증가시켜 최종적으로 disk-performance를 향상시킨다.
RAID 구조의 단점은 MTTF(mean-time-to-failure)가 감소한다는 것이다. 좀 더 쉽게 설명하면, 디스크의 평균고장시간이 100시간이 가정하자. RAID의 경우 여러개의 디스크들이 모여서 하나의 디스크의 역할을 하는 구조라서 각각의 디스크들은 평균고장시간이 상이 할 것이다. 그러므로 하나의 디스크를 사용할때는 평균고장시간을 100시간을 보장 받을 수 있는데, 여러개 디스크를 사용하면 하나의 디스크만 고장나도 완전한 기능을 보장 못하기에 평균 고장시간이 감소한다.
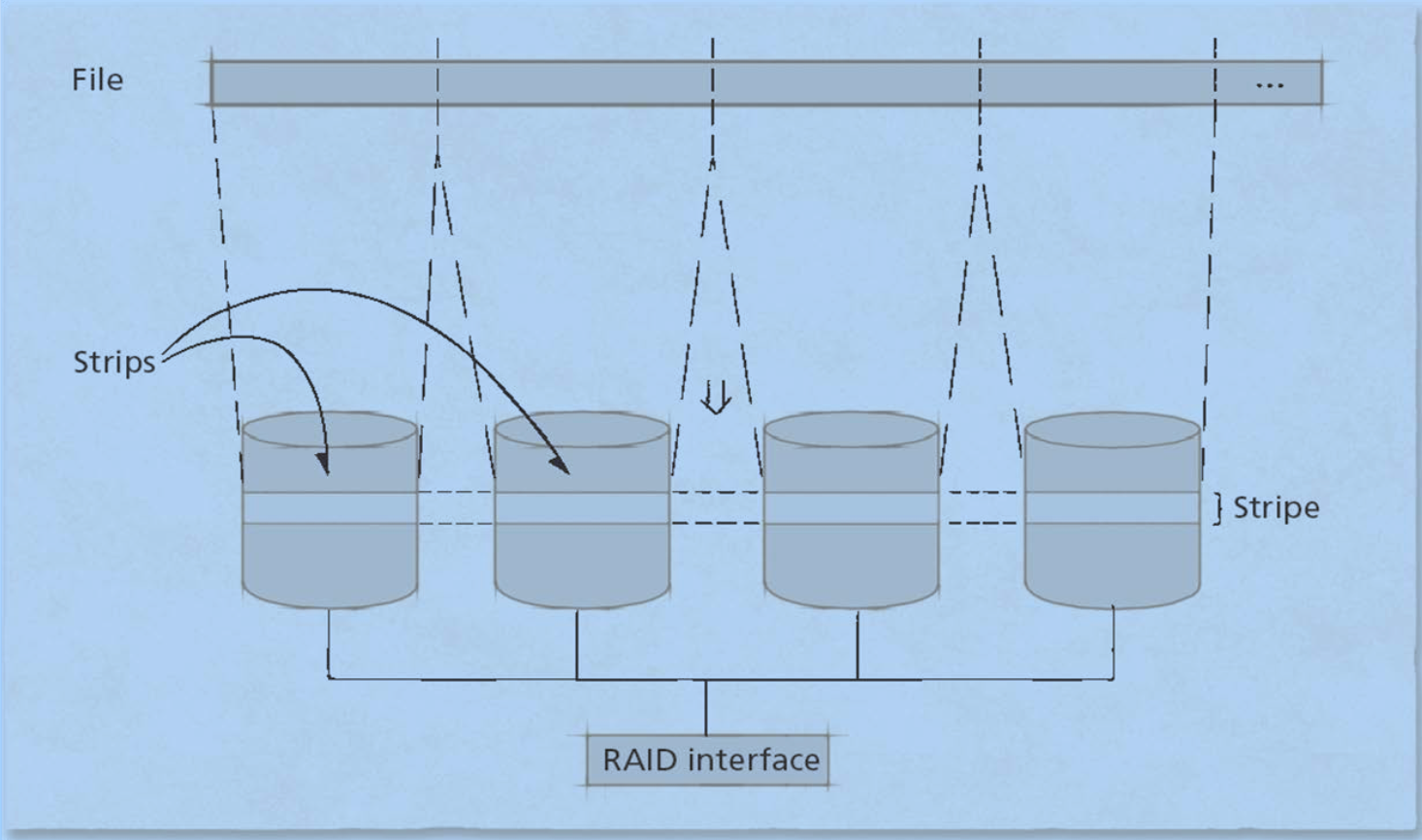
RAID에서는 Disk-Striping이라는 방법이 사용되는데, 이는 위에서 언급했듯이 여러개의 디스크들을 하나의 유닛으로 사용하면서, 저장될 데이터를 조각내어서 각각의 디스크들에 분산저장하는 방법이다. Disk-Interleaving이라고도 한다.
redundancy확보를 위해 Mirroring/Shadowing을 사용한다.이는 앞서 말한 데이터들을 여러군데의 디스크들에 분산 저장하는 방법이다. 미러링이라는 단어에서 유추할수 있듯이, 완전한 데이터를 그대로 다른 디스크에 복사해 놓는 행위이다. 이 방법 말고도 Parity-Check도 redundancy 확보를 위해 사용한다.
Disk Striping 이미지
Raid Levels
RAID 구조는 각각의 단계(Level)을 가지고 있다. 아래 그림에서는 0부터 6까지 있는데 숫자가 클수록 좀 더 발전된 형태라 보면된다.
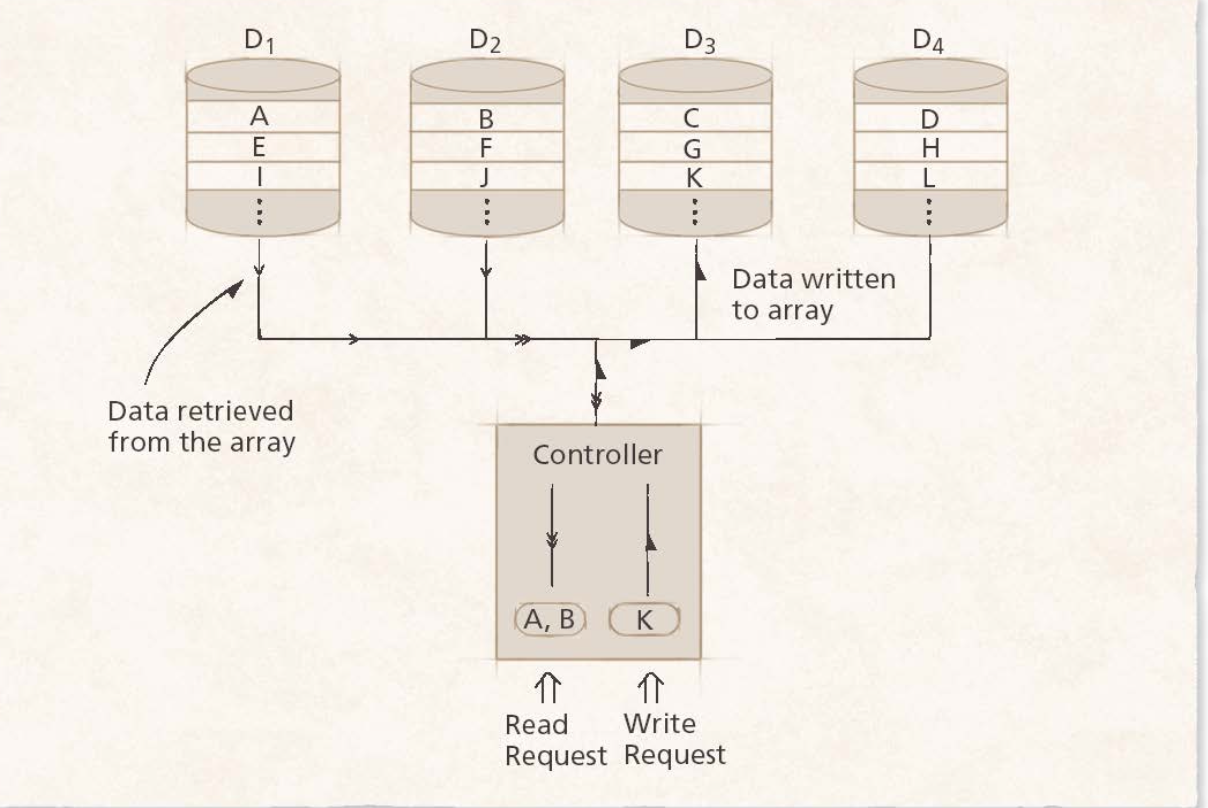
Level 0 : Striping만 하는 방식이다. 가장 단순한 형태이며, 저장될 데이터를 블록 단위로 쪼개어서 각각의 디스크들에 저장되는 방식이다. 이는 redundancy확보가 되지 않으므로 에러나 오류에 대한 방지가 없는 단계이다.
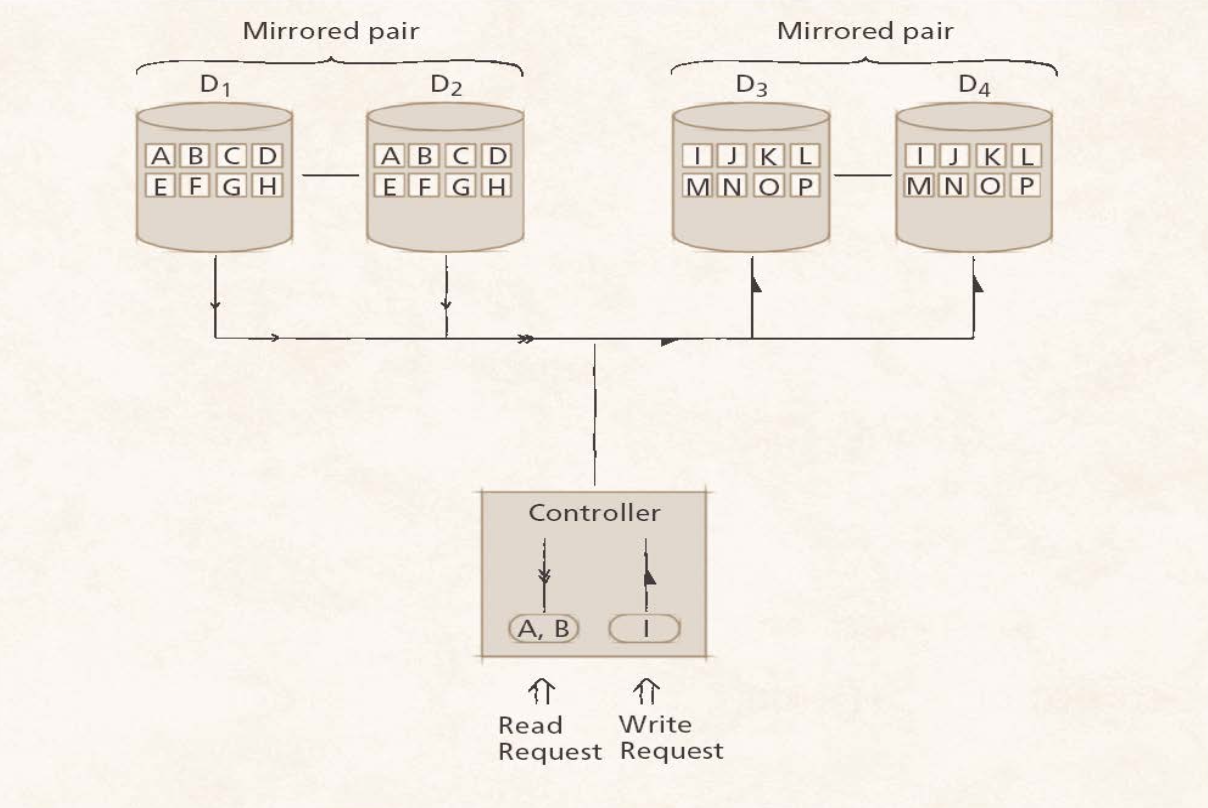
Level 1 : Mirroring을 사용하는 방식이다. 즉 그저 백업 데이터만 만들어 놓는 구조이다. 그래서 Striping을 하지않아 disk-performance가 떨어진다. 구체적으로는 데이터 Read시에는 같은 데이터가 두군데의 디스크에 저장되어서 좀더 빠르게 읽어 오는게 가능하지만, 데이터 Write할 경우에는 두군데에 써야하기에 성능향상은 없다고 본다. 공간효율성의 경우 1/n이다 (n은 디스크의 갯수)
Level 2 : redundancy와 striping 둘다 구현하는 방식이며 이와 더불어서 Hamming-Code를 사용하여 데이터의 오류 여부와 어는 곳에 에러가 생긴지 체크한다. 이 방식은 4개의 데이터가 비트는 3개의 hamming-parity를 가져야한다.(몇개에 몇개 이런식으로 정해져 있다)이 방법 또한 공간 효율성이 뛰어난 방식은 아니다. 또한 striping의 경우 블록 단위가 아니 비트 단위로 쪼개어서 넣어야한다.
Level 3 : 비트 단위의 Striping을 이용하며, 하나의 parity-bit를 위한 디스크를 사용한다. 하지만 오류가 발생했다는 사실만 알 수 있을뿐, 어디서 발생했는지는 파악하지 못한다. 또한 한번 데이터를 읽어들일때 모든 비트를 읽어야하는 단점이 있다. 공간효율의 경우 n-1/n으로 level2보다는 뛰어나다고 할 수 있다.
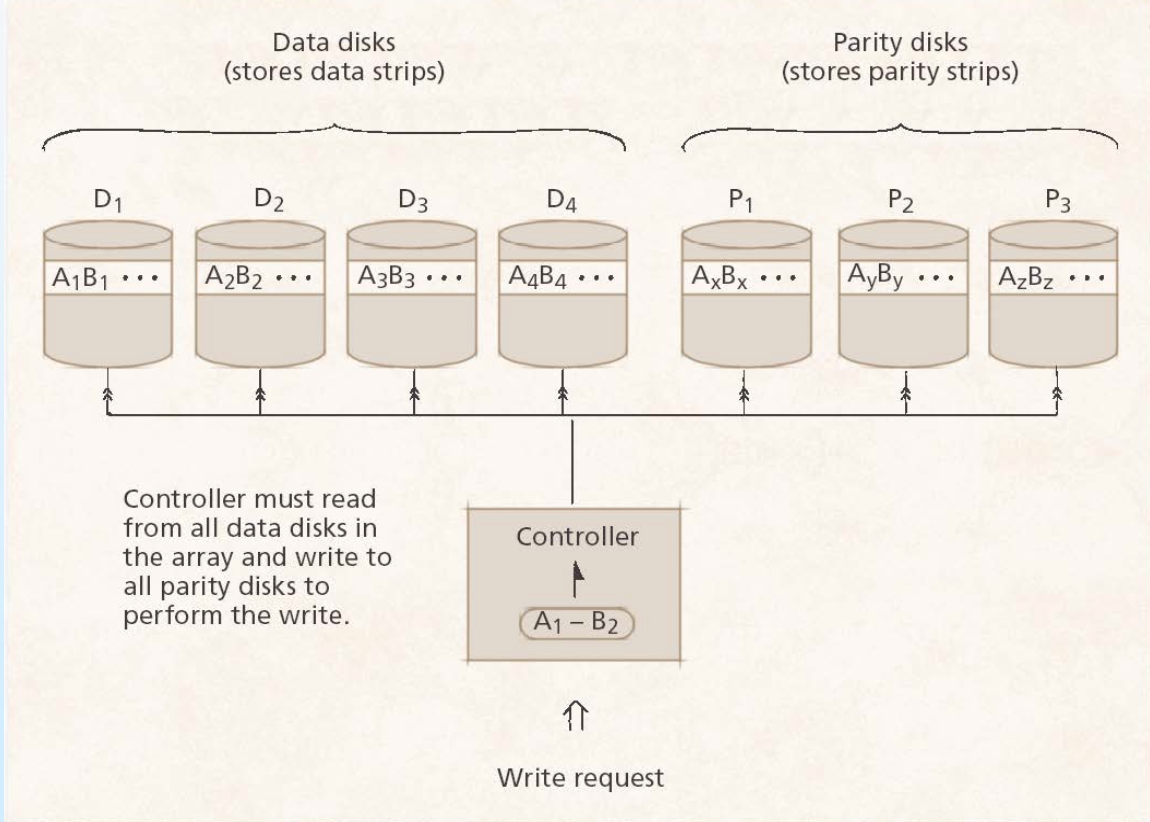
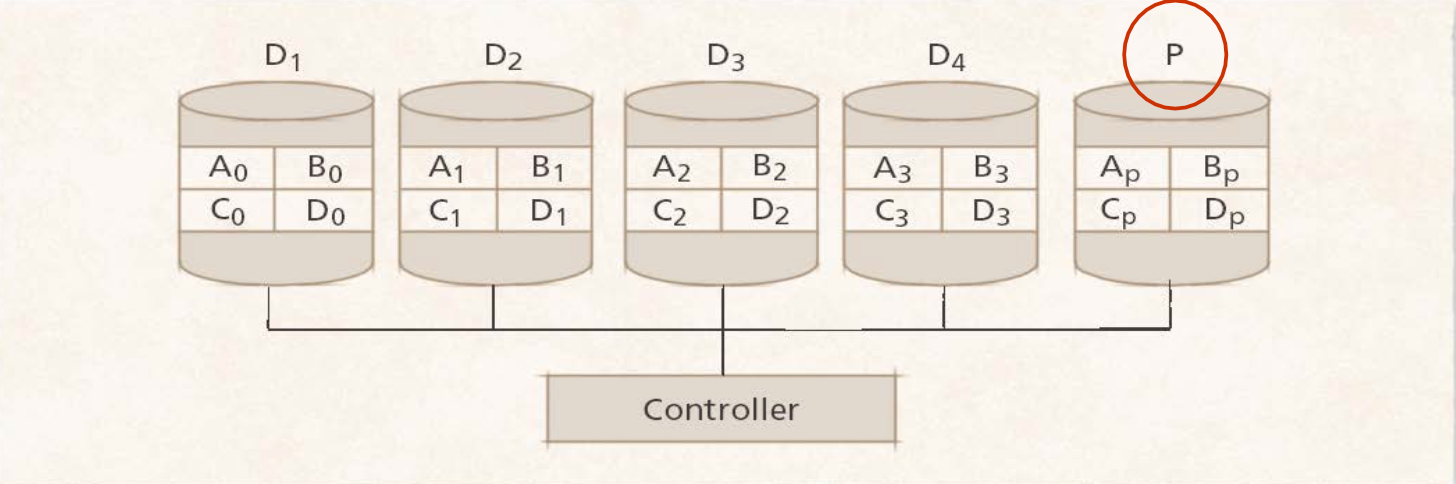
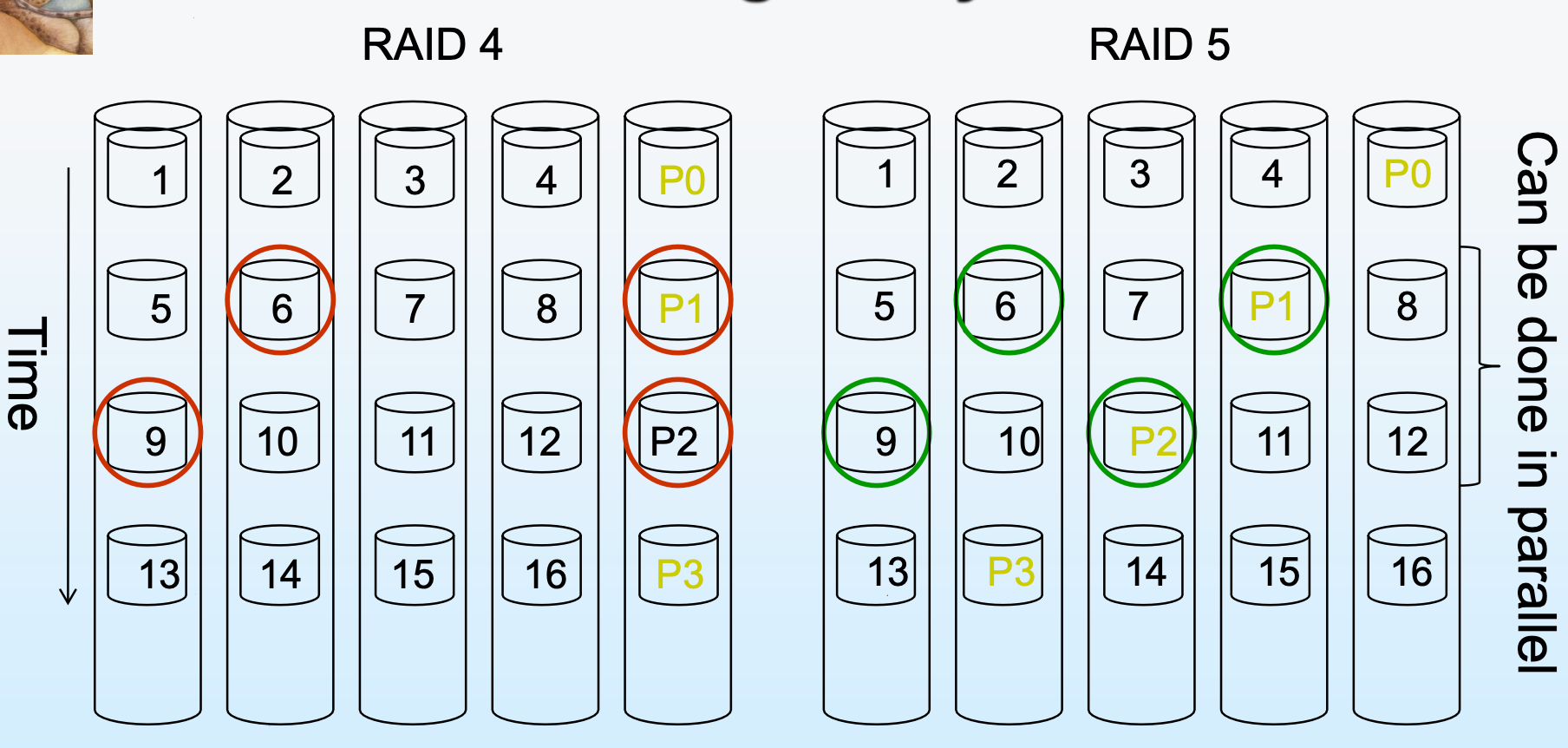
Level 4 : 블록 단위의 Striping을 이용하며, parity-block을 저장하는 한개의 디스크가 있다.공간 효율은 Level3와 동일하지만, read할때 모든 데이터를 다 읽을 필요가 없다는 면에서 Level3보다 발전된 방법이라 볼 수 있다.(small-write가능) 하지만 parity-block이 한군데의 디스크에 몰려있어서 write시 하나씩 밖에 쓰지 못하는 단점이 존재한다.
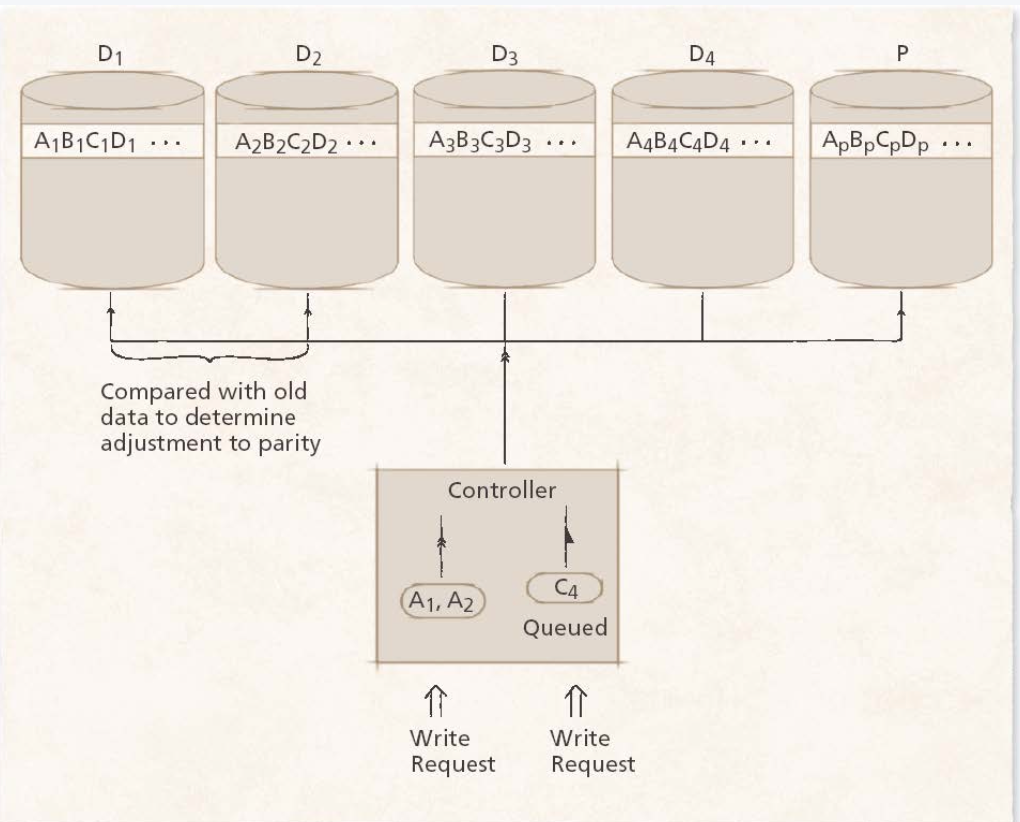
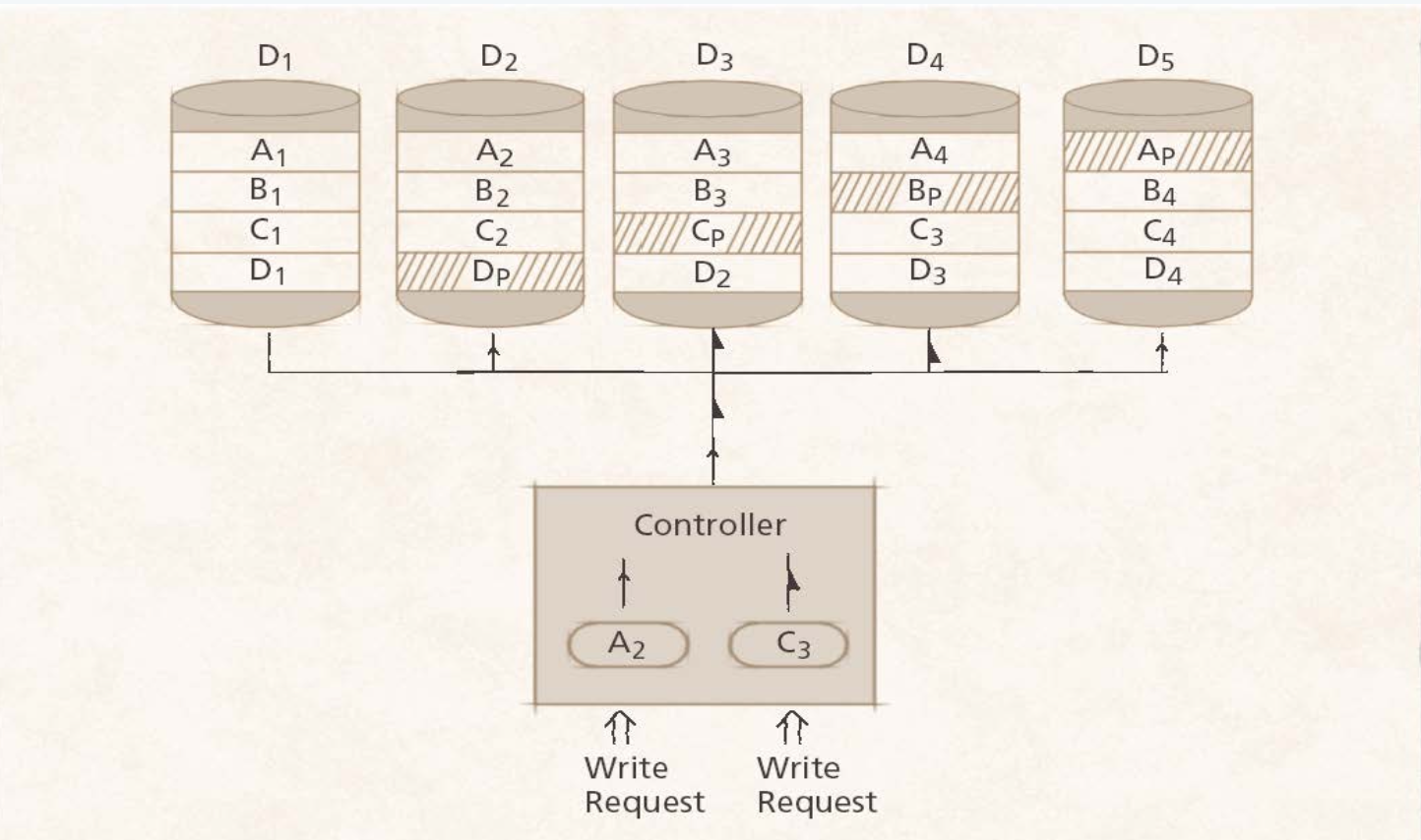
Level 5: Level 4의 언급된 단점을 보완한 방식으로, 구현 복잡도는 가장 복잡하지만 빠르고 훨씬 reliable한 방식이다. parity를 각각의 디스크마다 흩어 놓음으로써 read/write가 모두 동시에 일어나도록 한다. Parity 정보가 쓰려는 디스크에 있지 않은 이상 동시에 쓰기가 가능하다.
Distributing Parity Blocks 이미지(Level 4 vs Level 5)
RAID5 에서는 9,6이 동시에 write가 가능하다(parity-block이 분산되어 있어서)
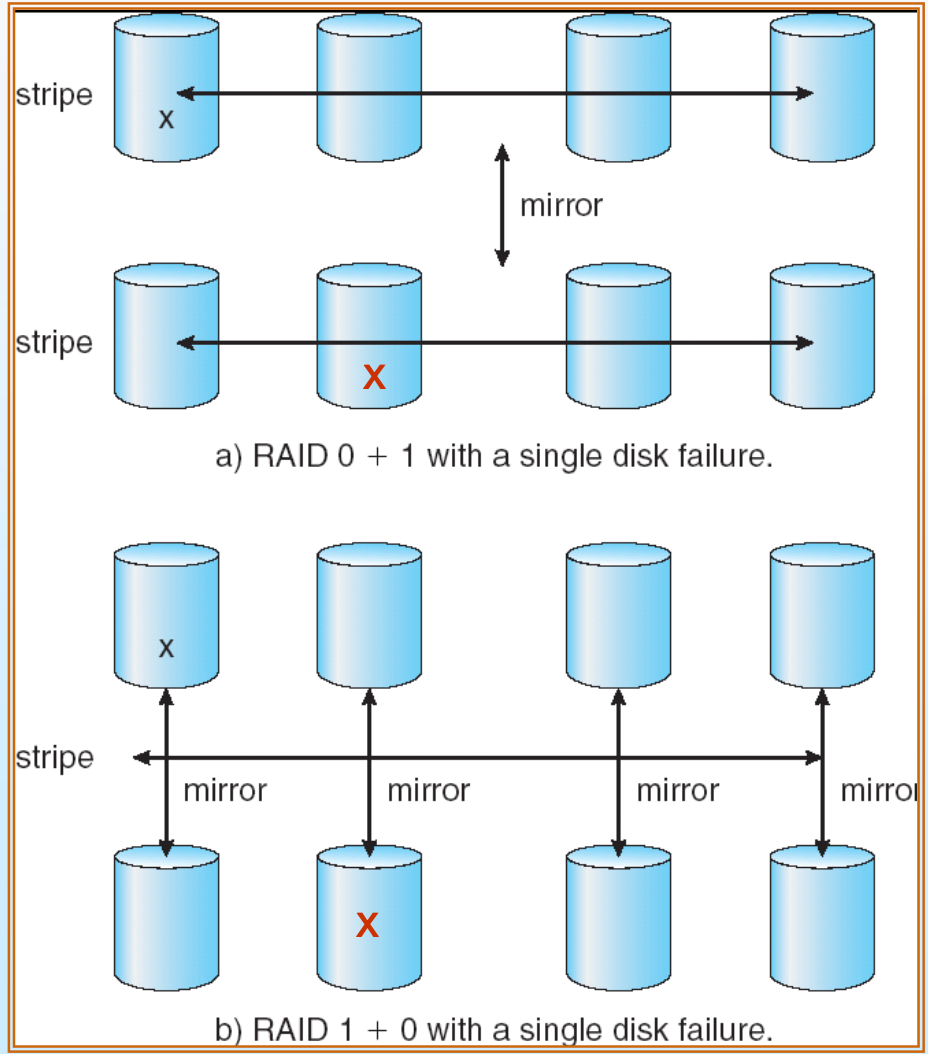
RAID(0+1) 과 RAID(1+0)의 차이점
아래의 그림처럼 각각은 다른구조를 가진다.
Single-failure와 Double-failure시 각각의 성능이 다르다.
Striping을 하고 Mirroring을 하냐 Mirroring을 하고나서 Striping를 하냐의 차이다.